The title of this post is an homage to a well-known paper by James Chapman called Type theory should eat itself. I also considered titling the post How I spent my Christmas vacation trying to construct semisimplicial types in a way that I should have known in advance wasn’t going to work.
As both titles suggest, this post is not an announcement of a result or a success. Instead, my goal is to pose a problem and explain why I think it is interesting and difficult, including a bit about my own failed efforts to solve it. I should warn you that my feeling that this problem is hard is just that: a feeling, based on a few weeks of experimentation in Agda and some vague category-theorist’s intuition which I may or may not be able to effectively convey. In fact, in some ways this post will be more of a success if I fail to convince you that the problem is hard, because then you’ll be motivated to go try and solve it. It’s entirely possible that I’ve missed something or my intuition is wrong, and I’ll be ecstatic if someone else succeeds where I gave up.
Recently on the mailing list, I proposed the following problem: show, in HoTT, that the 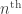
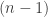
data Expr where Var : nat -> Expr U : Expr Pi : Expr -> Expr -> Expr Lam : Expr -> Expr -> Expr App : Expr -> Expr -> Expr
(This is for a type theory with one universe, with variables as de Brujin indices; don’t worry about the details.) The problem is then to define what it means for such an expression to be well-typed (that should be the easy part) and construct an interpretation function which sends each well-typed raw expression to an actual type (in this case, one living in the second universe).
Why would you want to do that?
This is what Dan Licata asked when I proposed the above problem. In particular, he was asking why you would want to use raw untyped syntax as the input.
What else could you do? Well, recently type theorists have come up with various more highly structured representations of type theory in type theory, which generally “re-use the ambient type-checker” rather than requiring you to implement your own. Chapman’s above-mentioned paper is one of these: he defines contexts, types, and terms by a joint inductive-inductive definition, ensuring that only well-typed things exist — i.e. if something typechecks in the ambient type theory in which the inductive-inductive definition is made, then it is automatically well-typed in the object theory as well. The definitions start out something like this:
data Context where Empty : Context _,_ : (G : Context) -> Ty G -> Context data Ty : Context -> Type where U : (G : Context) -> Ty G Pi : (G : Context) (t : Ty G) -> Ty (G , t) -> Ty G El : (G : Context) -> Tm G U -> Ty G data Tm : (G : Context) -> Ty G -> Type where ...
In other words, a context is either empty or the extension of an existing context by a type in that context; while a type is either the universe, a dependent product over a type in some context of a type in the extended context, or the type of elements of some term belonging to the universe. (I’m using Type for a universe in the ambient theory, and Ty for the dependent type (in the ambient theory) of types (in the object theory) over contexts. It’s not really as confusing as it sounds.)
This is an “inductive-inductive definition”, meaning that (for example) the type family Ty is dependent on the type Context, while both are being defined at the same time mutually-inductively. Coq doesn’t understand such definitions, but Agda does. (What I’ve written above isn’t quite valid Agda syntax; I simplified it for clarity.)
The advantage of something like this is that if you try to write something nonsensical, like App U (Lam (Var 100) U), then the ambient type checker (e.g. Agda) will reject it — whereas such gibberish is a perfectly good inhabitant of the type Expr above, that has to be rejected later by an typechecker you write. So why not use a representation like this?
I have several answers to this question; let’s start with the most philosophical one. I argue that if homotopy type theory is to be taken seriously as a foundation for all of mathematics, then in particular, it must be able to serve as its own metatheory. Traditional set theory, for instance, is perfectly capable of serving as its own metatheory: one can define the set of well-formed first-order formulas in an appropriate language, and prove in ZF that (for instance) any set-theoretic Grothendieck universe is a model of all the axioms of ZF. One can also construct “nonstandard” models such as forcing extensions (i.e. sheaf toposes). The same must be true of homotopy type theory; if it is to be a foundation for all of mathematics, it must be able to accomplish something analogous. (From a CS point of view, the corresponding point is that any general-purpose programming language must be able to implement its own compiler or interpreter.)
Now I would argue that to be completely satisfactory, this “serving as its own metatheory” must go all the way back to raw syntax. Why? Well, whether we like it or not, what we write on paper when we do mathematics (and what we type into a proof assistant as well) does not consist of elements of a highly structured inductive-inductive system: it is a string of raw symbols. (It’s actually even “more raw” than Expr is, but I’m happy to regard parsing and lexing as solved problems in any language.) The process of type-checking is part of mathematics, and so an adequate metatheory ought to be able to handle it.
I have other, more pragmatic, reasons to care about solving this problem. One of them is that we need a better handle on how to construct “nonstandard” models of HoTT, and being able to construct a “standard” model internally might give us a leg up in that direction. Also, again if HoTT is to be a foundation for all of mathematics, then it must be able to construct its own nonstandard models as well. However, none of that is what originally started me thinking about this problem.
Semisimplicial types
The problem of defining semisimplicial types, and more generally of defining and working with coherent structures built out of infinitely many types, is also one of the most important open problems in the field. It’s particularly tantalizing because it’s easy to write down what the type of n-truncated semisimplicial types should be for any particular value of n. Here are the first few:


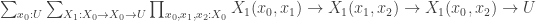
In fact, as Peter Lumsdaine has pointed out, it’s so easy that a computer can do it. I believe he even wrote a Haskell program that would spit out the Coq syntax for the type of n-truncated semisimplicial types for any n you like. But if we can do this, then with only a little extra effort (to prove termination) we should be able to write that same program inside type theory, producing an element of Expr. Therefore, if we could solve the problem I’m proposing, we ought to be able to solve the problem of semisimplicial types as well! Surely that’s reason enough to be interested in it.
What’s the big deal
So why is this problem hard? On the surface, it may seem like it should be completely straightforward. For instance, we could define predicates for validity of contexts, types-in-context, and terms-of-types-in-context, either inductively or recursively:
IsCxt : List Expr -> Type IsTy : List Expr -> Expr -> Type IsTm : List Expr -> Expr -> Expr -> Type
and then define our mutually recursive interpretation functions with a hypothesis of validity:
icxt : (G : List Expr) (JG : IsCxt G) -> Type1 ity : (G : List Expr) (JG : IsCxt G) (T : Expr) (JT : IsTy G T) -> (icxt G JG -> Type1) itm : ...
However, this is not as easy as it sounds, because of substitution. For instance, when is Var 0 a valid term, and what is its type? We are using de Brujin indices, which means that Var 0 denotes the last variable in the context. This variable of course has a type assigned to it by the context, which must be a valid type T in the context of all the preceding variables. The type of Var 0 must be this “same” type T, but now in the whole context (including the last variable of type T). With de Brujin indices, this means that the type of Var 0 is not literally T, but a “substitution” of it in which all the indices of variables have been incremented by one.
Therefore, our definitions of validity must refer to some notion of substitution. (This is true whether or not you use de Brujin indices; consider e.g. the type of App.) Substitution could either be an operation defined recursively on Expr, or represented by an extra constructor of Expr (“explicit substitutions”). But in either case, when we come to define the interpretation of Var 0 or App, we’ll need to know how the interpretation functions behave on substitutions: they ought to take them to actual composition with functions between the (ambient) types that interpret the (object) contexts.
Okay, fine, you may say (and I did): let’s just prove this as part of the mutual recursive definition of the interpretation functions. But I found that when I tried to do this, I needed to know that the interpretation functions also took composites of substitutions to composites of maps between types. At this point I stopped, because I recognized the signs of the sort of infinite regress that stymies many other approaches to semisimplicial types: in order to prove coherence at the 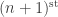
Why I should have known it wouldn’t work
When we build models of type theory in a set-theoretic metatheory, we do it by showing that from the syntax we can construct a certain algebraic structure which is initial, and that from our desired semantics we can construct another structure of the same type; the unique map out of the initial object is then the interpretation. I think it’s fair to say that morally, the attempted internal interpretation I described above is doing something similar inside type theory: we haven’t made the universal property explicit, but our ability to define a certain collection of functions by mutual recursion amounts to more or less the same thing.
Now in set theory, the algebraic structure we use is strict and set-level. In particular, it is fully coherent, because all coherence properties we might want hold on the nose, and so any higher axiom we might impose on those coherences also holds on the nose, etc. The syntactic structure is automatically strict and set-level by definition, but the semantics are not: the fact that they can be presented that way (e.g. an 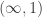
In type theory, it is no longer reasonable to expect to be able to present the desired semantics by a strict set-level structure. For instance, in general the universe need not admit any surjection from a set. However, the structure built out of syntax is still strict and set-level. Thus, in order to define an interpretation, we need a different sort of “coherence”. An inductive definition of the syntax allows us to sidestep the questions of what exactly this coherence might say and of what exactly the universal property is, by telling us directly what functions we can define by recursion. However, because the syntactic structure is in particular fully coherent (because it is set-level and strict), we shouldn’t expect to be able to define an interpretation except into another structure that is also fully coherent.
Now the ambient universe certainly is fully coherent. However, without already having something like semisimplicial types at our disposal, we don’t know how to express that fact. And therefore, we should expect to have a hard time doing anything which needs to use its full coherence — such as defining an interpretation of raw syntax.
I realize that this explanation is very hand-wavy and may not be convincing. If you aren’t convinced, please try to prove me wrong! I would be very happy if you succeed. But first allow me to bend your ear a little more with my failures. (-:
Structured syntax as a bridge
Rather than trying to go directly from raw syntax to the universe, we might try to use one of the structured inductive-inductive kinds of syntax I mentioned above as a stopping point halfway. This requires us to delve into the “…” I placed in the definition of the family Tm, which turns out to be surprisingly subtle, for the same reason as above.
Specifically, the constructors of Tm such as Var and App must involve a notion of substitution, and as before there are two obvious choices. We could make substitution an operation, in which case it must be defined inductive-recursively with the types Context, Ty, and Tm. Or we could make explicit substitutions a constructor of Ty and Tm, which keeps the definition merely inductive-inductive (though it requires adding a new type Sub of substitutions alongside Context, Ty, and Tm). Chapman’s paper that I already mentioned does the latter, while Danielsson did something closer to the former in a paper called A Formalisation of a Dependently Typed Language as an Inductive-Recursive Family (he actually only made substitution an operation on types, keeping it as a constructor for terms).
Dan Licata pointed me to a sneaky third option due to Conor McBride in a paper called Outrageous but Meaningful Coincidences, in which the syntax is essentially defined inductive-recursively together with its standard interpretation. This allows the object-language substitution to coincide with the actual notion of substitution in the ambient type theory.
As far as I can see, however, none of these can bridge the full gap from raw syntax to the universe. I admit that I haven’t tried McBride’s version; however, it seems so close to the universe itself that I would expect to have the same sort of problems as before. But it could be that something magical will happen, so it would be great if someone would try it. (It won’t be me, at least not in the near future; I’ve already used up more free time than I actually had in messing around with this stuff and in writing this blog post.)
I also didn’t manage to completely define an inductive-recursive version of type theory that does away with explicit substitutions entirely. As Danielsson notes in his paper, this is quite tricky because you have to prove various properties of the substitition operations as part of the inductive-recursive definition. In fact, I found myself wanting to include an encode-decode proof for the whole system as part of the inductive-recursive definition, in order to show that all the types were in fact sets! I didn’t complete the definition, but it may very well be possible to do. But the reason I gave up is that I decided it would almost certainly suffer from the same problem as the raw syntax: it would be set-level and strict, and so interpreting from it into the universe would require us to know and express the full coherence of the universe. (Also, I’m still wary of induction-recursion; I don’t think we know whether it is consistent with univalence.)
I think that what happens with Chapman’s inductive-inductive theory is most interesting and instructive. The situation here seems to depend on what you decide to do about judgmental equality. Chapman includes separate families for it in the inductive-inductive definition, i.e. in addition to Context, Ty, Tm, and Sub we have
data TyEq : (G : Context) -> Ty G -> Ty G -> Type data TmEq : (G : Context) (T : Ty G) -> Tm G T -> Tm G T -> Type
and perhaps one for context equality too. (Chapman actually uses a “heterogeneous” version, which has some advantages, I guess, but is harder to make sense of homotopically.) These families have a lot of constructors, representing all the usual judgmental equalities of type theory, and also things like symmetry, transitivity, and reflexivity, and that all the constructors of the other types respect judgmental equality. Finally, we have to include new constructors of Tm (at least) which “coerce” a term belonging to one type into a term belonging to a judgmentally equal one.
This definition has a setoidy feel to it, and so a homotopy type theorist may naturally think to try replacing it with a higher inductive-inductive definition, where instead of introducing new type families for judgmental equality, we re-use the (propositional) equality of the ambient theory. Now the previous constructors of TyEq and TmEq become path-constructors of Ty and Tm. Moreover, we can omit a lot of them completely, since actual equality is automatically reflexive, symmetric, and transitive, and respected by all operations. Similarly, we don’t need new constructors for coercion: it’s just transport.
Obviously the second option is attractive to me. I particularly like that it matches exactly what the Book says about judgmental equality in the introduction to Chapter 1: it’s the equality of the metatheory. However, the first (setoidy) has the advantage of existing in Agda already without postulates and thus being executable. But I think both have the same underlying problem.
For the HIIT approach, the problem is summed up by the question: are the types Context, Ty, and Tm h-sets? If we just blindly add path-constructors for every standard judgmental equality, the answer is surely not. Consider, for instance, the functoriality of explicit substitutions, which must be ensured by a constructor of judgmental equality. If the types in question were naturally h-sets, then this functoriality would be fully coherent, but there’s no reason this should be true without adding infinitely many higher-dimensional path-constructors to ensure it. (We can formulate the same question in the setoidy approach either by adding more and more “iterated” judgmental equality families, or by adding “higher coercion” constructors to the existing ones.)
On the other hand, we could add truncation constructors to force the types to be sets. (In the setoidy approach, we could do this by asserting that coercions along any two parallel equalities are equal.) This is more like what we do in the set-theoretic approach to semantics: the category of contexts is built out of syntax quotiented by the mere relation of judgmental equality. This would in particular make them fully coherent — but at what cost?
Consider what happens when we come to define an interpretation into the universe of the ambient theory. Most of it is straightforward: we use the induction principle of the inductive-inductive definition to define mutually recursive functions
icxt : Context -> Type1 ity : (G : Context) -> Ty G -> (icxt G -> Type1) itm : (G : Context) (T : Ty G) -> Tm G T -> ((x : icxt G) -> ity G T x)
In particular, by the recursion principle for higher inductive types, the clauses of these definitions corresponding to the path-constructors giving the judgmental equalities of the object theory must interpret them as propositional equalities in the ambient theory. (With the setoidy approach, we would define separate mutually recursive functions on TyEq and TmEq that do this interpretation.) However, if we included truncation constructors, then we’re sunk, because the universe is not a set. In set-theoretic semantics, we can get away with truncation by using a strictification theorem saying that the desired target universe can be presented by a set-level structure (e.g. a model category), but inside HoTT this is not true.
If we leave off the truncation constructors, then we’re basically okay: we do get an interpretation into the universe! (There’s an issue with domain and codomain projections for equality of Pis in the setoidy approach, but I think it can be dealt with and it’s not relevant to the point I’m making here.) Now, however, the problem is on the other side, with the interpretation of raw syntax into the structured version. When we write raw syntax on paper, we don’t ever indicate which judgmental equality we are coercing along. So although this isn’t by any means a proof, it seems (and my own experiments bear this out) that we’re going to get stuck either way.
Of course, I am aware that Vladimir has proposed a type theory in which judgmental equalities are indicated explicitly. But I have yet to be convinced that this is practical, especially if one admits the possibility of distinct parallel judgmental equalities. I strongly suspect that in practice, we constantly identify terms that are “actually” coercions along different-looking judgmental equalities. My evidence for this comes from my attempts to interpret raw syntax into inductive-inductive syntax, and also from something else I tried (in fact, the first thing I tried): defining directly the inductive-inductive syntax for semisimplicial types without going through raw syntax. In both cases I found myself needing higher and higher coherences for functoriality.
Of course, if we already knew how to solve the problem of infinite objects (such as, for instance, by having a useful theory of semisimplicial types), then we might be able to actually put all the higher coherences into the inductive-inductive definition. I would hope that we could then prove that the types involved were h-sets, and then use that to interpret the raw syntax.
So in conclusion, my current impression is that solving this problem is about equally hard as solving the problem of infinite objects. But I would love to be proven wrong by a solution to the problem of interpreting raw syntax!
Postscript: which equalities can be made judgmental?
Recall that the interpretation functions of inductive-inductive syntax map judgmental equality of the object theory to propositional equality of the ambient theory. In particular, any equality which holds propositionally in the ambient theory can be made to hold judgmentally in the object theory, by simply adding a path-constructor for it, with an appropriate clause in the interpretation function mapping that constructor to its ambient propositional version.
This may seem to suggest that the answer to the question of “what propositional equalities can be made judgmental” is “all of them!” However, remember that in order to interpret raw syntax, we probably need the inductive-inductive syntax to consist of h-sets, and throwing in new path-constructors has a way of destroying such properties. So the answer is really, “anything which holds propositionally, and can be proven to be fully coherent with all the other judgmental equalities”.
The relationship of this answer to the one provided by traditional set-theoretic semantics is, roughly, the same as the relationship between the two kinds of coherence theorem in category theory: one which says “all diagrams (of a certain form) commute”, and one which says “every weak structure is equivalent to a strict one”. In set-theoretic semantics, where judgmental equality is interpreted by on-the-nose equality in a strict structure (such as a contextual category), in order to add new judgmental equalities we need to prove a coherence theorem of the second sort, showing that they can be modeled strictly. But in the native HoTT semantics that I’m hoping will exist, we can add new judgmental equalities by proving a coherence theorem of the first sort. Category-theoretic experience suggests that the first sort of coherence theorem is more general and useful; for instance, there are contexts in which “all diagrams commute” in an appropriate sense, but not every weak structure is equivalent to a strict one.
Finally, I think this gives a very satisfactory answer to the philosophical question of “what is judgmental equality?”. The judgmental equalities are just a subclass of the (propositional) equalities which we’ve chosen, by convention, not to notate when we transport/coerce across them. But in order for this to be consistent, we need to know that no real information is lost by this omission; and this is the requisite coherence theorem.

My understanding of the proposal for a judgmental equality type was that it would act like NuPRL’s equality type, and so there could not be distinct parallel judgmental equalities. But I guess I don’t understand why witnesses would be carried around. Is there a write-up of Vladimir’s proposal somewhere?
Do you have any examples (of different-looking judgmental equalities, and what you mean by “terms that are ‘actually’ coercions”) that I can play with? The first thing that comes to mind for me is that even though I want
sym (sym p) ≡ p, there are potentially multiple proofs thatsym (sym p) = p(in fact, we have(sym (sym p) = p) = (p = p)). Furthermore, the way that I envision granting judgmental equality says that the canonical proof ofsym (sym p) = pwon’t reduce torefl, even though it is the path which justifiessym (sym p) ≡ p. (It will be equal torefl, but only propositionally.) (This is similar to the case of eta for records.)I think Vladimir’s reason for carrying around witnesses was that otherwise, type-checking wouldn’t be decidable.
By ‘terms that are “actually” coercions’ I mean terms that, when “compiled” into the inductive-inductive syntax, involve coercions (we don’t normally write coercions). And I’m not even thinking of proofs of equality that are actually different in the sense of being unequal paths; rather I’m thinking of equalities that are the same path, but we just need arbitrarily much coherence data to tell us that they are.
Just to make sure I understand you, is
(λ n : ((λ T ⇒ T) ℕ) ⇒ (n : ℕ))an example of such a term, because it involves transportingnalong a judgmental β reduction? And, for example, we want to know that the two orders of judgmental β reduction on(λ n : ((λ f x ⇒ f ((λ T ⇒ T) x)) (λ T ⇒ T) ℕ) ⇒ (n : ℕ))are coherent in an appropriate way?Kudos for writing up in this detail your current thoughts on a topic we can’t yet say much about formally!
I don’t consider it a coincide that I ran into the exact same problem of internally reflecting the semisimplicial structure of context weakening and representing the “full coherence”, as you say, necessary for the interpretation in my own failed attempts of internalizing type theory last autumn (in fact, in an interview, the reference to Chapman in your title apparently got me a post doc 😛 — assuming I can finish my thesis…).
It was discussions with Nicolai Kraus and Paolo Capriotti here in Nottingham, who had been thinking about semisimplicial types for quite some time, that led me appreciate the difficulty of the problem. There ought to be some kind of metatheorem making precise the intuition that they don’t exist.
Yes, I occasionally wonder about this as well. Sometimes it feels kind of like how natural numbers objects (or more generally infinite constructions) don’t necessarily exist in an elementary topos, because the category of finite sets is such. But of course in this case we are assuming lots of infinite constructions, including the natural numbers, and there are even some infinite structures of type dependency that we can define easily, like towers and globular types. Somehow it feels like what’s different about semisimplicial types is that the “complexity” also diverges as we go to infinity, rather than staying constant, but it’s unclear to me how to make that precise, or construct a model in which structures of “divergent complexity” don’t exist even though some infinite structures do.
Because solved cases are useful sometimes, there is (or ought to be) a higher-equational theory of loopspace objects: Milnor’s deelooping construction (which is built on Ganea’s theorem, which is a case of flattening…) shows that a space is a loopspace whenever there are sequences
is a loopspace whenever there are sequences 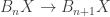 and maps
and maps 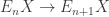 such that the sequences
such that the sequences  are cofibers and
are cofibers and 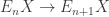 is the pullback of
is the pullback of 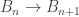 ; everything we’ve said so far is about spaces, maps, and universal 2-cells. Stasheff contributes that this is equivalent to a continuously-parametrized system of equations, the
; everything we’ve said so far is about spaces, maps, and universal 2-cells. Stasheff contributes that this is equivalent to a continuously-parametrized system of equations, the  -forms — his point seems to have been that for some purposes the
-forms — his point seems to have been that for some purposes the  -forms are more convenient, but here I’m emphasizing the opposite convenience: the
-forms are more convenient, but here I’m emphasizing the opposite convenience: the  -forms and the coherences between them are equivalent to a very-low-dimensional yet-infinitary structure. (This exercise may look silly in that we can already say “let
-forms and the coherences between them are equivalent to a very-low-dimensional yet-infinitary structure. (This exercise may look silly in that we can already say “let  the fiber of all the maps
the fiber of all the maps  ; and the needed theorem is that the colimit of these pullbacks is again a pullback — which is an infinitary, but still-low-dimensional case of flattening.
; and the needed theorem is that the colimit of these pullbacks is again a pullback — which is an infinitary, but still-low-dimensional case of flattening.
_ : equiv X (loospace Y)” in a suitable context, but never mind that for now). Oh, there’s a (flat) infinitary fact that still should (I think) be straight-forward: there are sequences of pasting-lemma pullbacks that makeIn fact, Milnor’s construction shows more (at least in the CW category): for instance the delooping of is (the basepoint component of)
is (the basepoint component of)  ; but this, I think, is further than HoTT ought to stretch itself, because I’m not sure it’s true in other settings. It looks like more than ought to be true in (say) a Bredon-Equivariant setting, if only because there should be more loopspace-like functors than
; but this, I think, is further than HoTT ought to stretch itself, because I’m not sure it’s true in other settings. It looks like more than ought to be true in (say) a Bredon-Equivariant setting, if only because there should be more loopspace-like functors than  .
.
Sorry, I can’t figure out what you’re talking about. I assume that that and
and 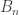 mean the same thing, and that there is also a family of maps
mean the same thing, and that there is also a family of maps 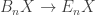 which you didn’t mention, but how is the whole sequence related to
which you didn’t mention, but how is the whole sequence related to  ? Can you give a citation?
? Can you give a citation?
There is Milnor 1956, which seems to suppose a strict group; Stasheff 1963 completes the homotopification of the argument, and introduces $A_n$-forms.
… and …
…
Okay, so the closest thing I’ve found in Stasheff to what you’re talking about is his definition of an “ -structure”, which (in the limit
-structure”, which (in the limit 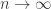 ) is a sequence of maps
) is a sequence of maps 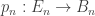 and commuting inclusions
and commuting inclusions  and
and  , with
, with  and
and  , such that each
, such that each  is a fiber sequence, and compatible contracting homotopies
is a fiber sequence, and compatible contracting homotopies 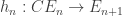 . Is this what you’re talking about?
. Is this what you’re talking about?
That’s the first definition in his paper; look for the phrases “rectitude of thought” and “cloud of unknowing” to follow, leading up to Proposition 3. He later outlines that this -structure is more general than necessary, showing (via Propositions 10 and 11) how the sort I’ve described can be recovered from a
-structure is more general than necessary, showing (via Propositions 10 and 11) how the sort I’ve described can be recovered from a  -form; the other direction of Theorem 5 is that an
-form; the other direction of Theorem 5 is that an  -structure gives an $A_n$-form, and he gives that part of the argument in Section 4.
-structure gives an $A_n$-form, and he gives that part of the argument in Section 4.
His Theorems 10 and 11 construct an -structure from an
-structure from an  -form (the latter apparently meaning, in modern language, an action by the associahedra operad). I can’t find any definition in the paper that looks more like what you’re describing than his definition of
-form (the latter apparently meaning, in modern language, an action by the associahedra operad). I can’t find any definition in the paper that looks more like what you’re describing than his definition of  -structure (nor have I been able to extract a precise definition from what you’re describing).
-structure (nor have I been able to extract a precise definition from what you’re describing).
What I am describing is a special -structure, specifically the canonical
-structure, specifically the canonical  structure of a
structure of a  -form. I mention it because canonical-
-form. I mention it because canonical- -structure is trivial to define in HoTT, but is known in classical homotopy (from Stasheff) to be equivalent to an operations-equations-and-coherences theory, specifically that of
-structure is trivial to define in HoTT, but is known in classical homotopy (from Stasheff) to be equivalent to an operations-equations-and-coherences theory, specifically that of  -forms.
-forms.
Sorry, I don’t see how what you described is an -structure in Stasheff’s sense, let alone the canonical such of an
-structure in Stasheff’s sense, let alone the canonical such of an  -form (since you didn’t mention any operations in your description of it).
-form (since you didn’t mention any operations in your description of it).
Look, we can even leave out the specific construction I’ve tried to give (in which it’s possible that I’ve negelected, through a year’s worth of forgetting, a uniformly-bounded locally-finite amount of data) and see that Stasheff himself gives a sufficient criterion [ -structure] for having operations and coherences [
-structure] for having operations and coherences [ -form], and such that the former is trivial to define in HoTT, even in the case
-form], and such that the former is trivial to define in HoTT, even in the case  .
.
(( It happens by accident-of-history that this is telling the story backwards: the -structure was implicitly present in Milnor’s delooping and Stasheff’s job was to find out what equations were actually used in it; and we can give a quick answer to that, too: the limit of the
-structure was implicitly present in Milnor’s delooping and Stasheff’s job was to find out what equations were actually used in it; and we can give a quick answer to that, too: the limit of the 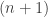 -fold cospan consisting of
-fold cospan consisting of  copies of
copies of  is
is  , and there’s an essentially unique cube of pullbacks whose
, and there’s an essentially unique cube of pullbacks whose  -skeleton (forgetting
-skeleton (forgetting  ) encodes precisely an $A_n$-form on $\Omega B$. ))
) encodes precisely an $A_n$-form on $\Omega B$. ))
Well, Stasheff’s definition involves the notion of “subspace”, which we don’t have available in HoTT.
There is, of course, another sufficient criterion for having operations and coherences that is trivial to define in HoTT, namely an equivalence . (-: I gather that
. (-: I gather that  -structure is supposed to be “intermediate” between this and the
-structure is supposed to be “intermediate” between this and the  -form.
-form.
We can leave off “subsapce”; it’s not really important. But the structure/form relation is nicer than -form=
-form= -structure=loopspace, in that we have the same filtration of structuredness on either side: spaces that support
-structure=loopspace, in that we have the same filtration of structuredness on either side: spaces that support  -forms but not
-forms but not 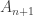 -forms also have
-forms also have 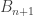 s but not
s but not  s.
s.
I don’t know what you mean by “leave off” subspace.
‘Leave off “subspace”’ as in : it’s the word Stasheff needed to be constructing a particular set-and-topology; since we’re not topologizing sets, we can ignore the word, or read it as “map” or whatever.
Stasheff himself remarks that the coherence condition isn’t necessary; it just makes his paper shorter.
If we do that, then I don’t know how to make sense of his coherence condition on the contracting homotopies without turning it into infinitely many data.
Crazy idea: If we work in a type theory with higher-ly-judgmental inductive types (judgmentally truncatable inductive types?), i.e., where we can add constructors to an inductive type for judgmental equalities, do the coherence problems go away?
What makes you think that they would?
As I understand it (and, please, correct me if I’m wrong), two essential properties of strict/judgmental equality are: (1) it implies propositional equality, and (2) all witness of a judgmental equality are judgmentally equal. (I still haven’t found a presentation of Vladimir’s proposal, though, so I’m not fully sure about the details.) In particular, we can have all witness of a judgmental equality x ≡ x be judgmentally equal, even if the propositional path space x = x is non-trivial. (This seems to me to be a restatement of the “fully coherent” property; it is a property that is, in some sense, somewhere between “these points are propositionally equal” and “the path space between these points is contractible”.) So my hypothesis is that strictly truncatable inductive types would give you a type for “things which are fully coherent”, and you get to postulate the coherence for free on one side (the structured syntax) and you get it automatically for free on the other side (the interpretation in the universe).
I’m half listening to this conversation. I’m sorry if I’m butting in, but maybe you should use a different term than “judgmental equality”, because if it’s a judgement, then you can only talk about it in the metatheory. If it’s a type, then it’s not judgmental equality. That is, unless you use syntactic reflection, but you don’t seem to be talking about that.
Maybe you should just call it strict equality.
There’s no such thing as “butting in” to a public conversation on a blog; anyone and everyone is welcome!
I think you’re absolutely right. Vladimir did have an earlier proposal which kept track of witnesses for judgmental equalities without reifying them as types, and at first I thought Jason was talking about something like that. But if what we’re talking about is Vladimir’s more recent proposal in which there are two identity types, one with a reflection rule and one without, then I agree that the term “judgmental equality” for the stricter one is indeed inappropriate. Vladimir calls it “exact equality”; I like “strict equality” better. (The reflection rule means that two terms are strictly equal just when they are judgmentally equal, but it’s still important to separate the type from the judgment.)
However, I currently find that proposal to be unacceptable for a different reason: it’s not homotopy invariant at the level of models. One can have distinct model categories and
and  which present the same underlying
which present the same underlying 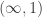 -topos, and yet whose “internal type theories with strict equality” are different, even if you look only at the “fibrant” types. Granted, with current technology we don’t know how to model any type theory in an
-topos, and yet whose “internal type theories with strict equality” are different, even if you look only at the “fibrant” types. Granted, with current technology we don’t know how to model any type theory in an 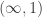 -category without presenting the latter by a model category, but at least in “HoTT v1.0” we can hope to prove that the resulting “internal language” is presentation-independent, since all the type-forming operations are homotopy invariant.
-category without presenting the latter by a model category, but at least in “HoTT v1.0” we can hope to prove that the resulting “internal language” is presentation-independent, since all the type-forming operations are homotopy invariant.
It seems like we’re on the same page with your second paragraph. I don’t understand the difference in connotation between “exact equality” and “strict equality”. They seem to be getting at the same thing to me. I just figured “strict” was already widely used in higher category theory.
I don’t fully understand the third paragraph, but it’s interesting. It sounds like a design problem. 🙂 You’re saying that because of families that only respect strict equality, you get to learn too much about the hset-level construction of higher h-level types? It would be a shame if a HoTT with strict equality cannot be designed that’s acceptable to homotopy theorists, because strict equality is very useful for computational reasons! Basically, strict equality doesn’t “do” anything, it doesn’t have witnesses that let you transport, which would need to be around at runtime in order to run them. A programmer would want to arrange strict equality as much as is practical in order to avoid coercions at runtime. Come to think of it, this is the same issue, just that programmers _want_ to know the representation, and mathematicians want to _not_ know. 😀
The reason I prefer “strict” is exactly because it’s already widely used in higher category theory. I don’t get as much intuition from “exact” that I do from “strict”.
Sort of, except that in general, higher types are not “constructed” out of hsets. Actually, that’s kind of the problem: too much strict equality forces higher types to have “underlying” hsets in a way which they shouldn’t. Put differently, you might choose to “implement” strict equality in various ways without changing the homotopical content of type theory, but the current proposal for reifying strict equality exposes too much of those implementation details. I’m not necessarily entirely against reifying strict equality, but I think it needs to be implemented in a homotopy-invariant way.
Let me see if I understand you using a thought experiment.
ITT with no extra axioms can be modeled with just hsets. But because it’s a subtheory of HoTT, it can also be modeled with X, for any X which is fancy enough to model HoTT. X are not generally hsets because univalence contradicts this internally. So we can think of ITT equality as “strict” by thinking about the hset model, but it’s homotopy-invariant because HoTT is and it could be modeled with X.
Now we add “strict” equality to HoTT by having the “non-fibrant” parts work with an equality specified by ITT, and meanwhile univalence and HITs work with weak equality. To model this system, you could use hsets for the ITT fragment, and X for the HoTT fragment, or you could use X for the ITT fragment already, and then, depending on what rules you provide for explicitly reasoning about the “fibrant” parts using “strict” equality, the model for the HoTT fragment would generally have to be something even fancier than X. Maybe X internalized in the category of X.
Am I making any sense?
If so, am I talking about something like the system you’re getting at?
No, the thing that makes an equality “strict” is that it satisfies the reflection rule, which is not part of ITT and not satisfied by univalent models.
Darn. In that case, I don’t know what you’re talking about. But I’m glad it doesn’t involve ITT equality. I like the equality reflection rule. 🙂
The weak equality of HoTT is the same as ITT equality (plus things like univalence).
Right, I knew that much. I’m strong on the type theory side of things. What I meant is I’m glad the strict equality you have in mind isn’t ITT equality.
Here’s an idea for how a theory that reifies strict equality might nevertheless be homotopy-invariant. Vladimir’s proposal includes a notion of “fibrant types” which are “locally” homotopy-invariant, in the sense that any construction in a fibrant type can be transported across any path-equality — and hence across any equivalence of types, since path-equalities satisfy univalence. They are not “globally” homotopy-invariant in the sense I described above, but I can imagine there might be a type theory with strict equality and a stronger notion of “fibrancy” such that any construction in the strongly-fibrant types is homotopy-invariant even in the global sense.
Here’s another way to say it. The traditional philosophy of homotopy theory is that it’s okay to use non-invariant notions if at the end what you construct is invariant. The problem with this is that you then have to do all the work of showing that what you get is invariant. One of the great advantages of homotopy type theory as it stands is that everything (that we can say internally) is automatically invariant, and I don’t want to give this up completely. The idea above would be a compromise in that not every internal statement is invariant, but there is nevertheless a syntactic criterion for invariance, so that we could still be sure that as long as what we say is type-correct (and belongs, in the end, to a strongly-fibrant type) then it is automatically invariant.
OK, so I don’t understand the details of local vs global homotopy-invariance, or even really what homotopy-invariance is. But the gist of what you’re saying sounds good. In programming, it’s great when you can work in a high-level language, which is most of the time. But some problems just aren’t well suited to the “fancy” concepts a high-level language takes as primitive. You could do it in the high-level language, but it won’t really be any easier than in a lower-level language, and it’ll just run slower, use more memory, etc. So a flexible platform allows you to “drop down” into a lower-level language to do parts of the development, and then somehow tie that work together with the stuff expressed in the high-level language. Almost every well-known high-level language supports this in some way; it’s just a really pragmatic thing to have.
What you’re proposing now seems analogous. You can “drop down” to working with strict equality, and this sacrifices some properties by default. Like how Haskell code will catch its own errors and crash with an exception, but C code will crash when the hardware catches it doing something illegal. But if your C code is well-behaved, then in principle you can use it from Haskell without incident. Otherwise Haskell becomes “as bad” as C. Likewise, you can do “bad” (or maybe “evil”) things with strict equality, but if you prove that your development is not so bad after all, then you can use it from the world of weak equality without changing the semantics of weak-equality-respecting code.
Am I on the right track?
Yes, that seems like a good analogy.
But the coherence problems apply to all types. So even if you could construct some judgmentally-truncated ones where the problems go away, how would that help with all the other types?
I’m not sure what you’re asking, so I’m going to try to pinpoint what I think I said, in the hopes that you can point to same aspect of it where I can look for your question.
My understanding of the problem with the Raw Syntax -> untruncated HIIT Structured Syntax -> Interpretation was that you have trouble with first arrow because you need to determine the coherent paths along which you coerce; the problem with the Raw Syntax -> truncated HIIT Structured Syntax -> Interpretation was that you have trouble with the second arrow because the universe is not an hSet. My proposal is to adapt the second of these, making it Raw Syntax -> judgmentally truncated HIIT Structured Syntax -> Interpretation; the judgmental truncation means that the paths in the structured syntax are automatically coherent (allowing us to keep the first arrow) but don’t cause the type to be an hSet (removing the obstruction to interpreting it into the universe).
Oh, I misunderstood what you were proposing. Also I misunderstood what you meant by “judgmental truncation”. (Now I have no idea what you mean by it.) But in any case, I don’t think it would help, because the coherence of the raw syntax is propositional, not judgmental, so the coherence of the structured syntax also needs to be propositional.
I am proposing that, if we denote propositional equality as Id x y, and judgmental equality as Strid x y, then we permit inductive types to have constructors which land in Strid. So, for example, we could write
and get the strict (-1)-truncation, which is judgmentally contractible. I used “truncated” rather than “higher” because, as I understand it, “higher” judgmental paths are all trivial, so “higher” is a mis-nomer. (That is, you are not adding higher structure, but collapsing it.)
Isn’t the raw syntax an hSet? What coherence (propositional or otherwise) does it have? Alternatively, can I find your code/definitions of what you’ve attempted somewhere online?
In the ordinary (-1)-truncation, the path constructor takes two points of the truncation, not of the original type, and this is essential for showing that it is in fact truncated. Did you mean to do it that way for the judgmental case as well? If so, then I fail to see how this doesn’t force the type to be also (-1)-truncated in the usual sense (you claimed above that a judgmental truncation wouldn’t force the type to be an hset and thus wouldn’t destroy the interpretation into the universe). If not, then I fail to see how it accomplishes any coherence.
Also, it seems that you must also be proposing to extend the syntax of type theory so that we can hypothesize judgmental equalities (otherwise we couldn’t write an induction principle for such things). I am dubious that this makes any sense, so I’d kind of like to wait on discussing it until I see an actual proposed type theory that I can look at.
The raw syntax is an hset — propositionally, not judgmentally. It is coherent because it is an hset; therefore its coherence is also propositional.
Yes.
It does, in this case. However, I am not proposing that we judgmentally truncate the HIIT of structured syntax after defining it. (My choice of wording was very poor, but I don’t have a good name for these types-with-constructors-that-can-land-in-Strid.) I am talking about replacing the (non-coherent) path constructors in the HIIT of structured syntax with constructors that land in Strid, which are thus automatically coherent.
You are right, I am proposing that we extend the syntax to allow hypothesizing judgmental equalities. (Just having a “strict (-1)-truncation operator” isn’t sufficient.) I have asked on the HoTT mailing list for a write-up of Vladimir’s proposal, if such exists; hopefully the response will be sufficiently concrete. Perhaps I should ask Dan Grayson if https://github.com/DanGrayson/checker allows postulating judgmental equalities, or ask Andrej Bauer if https://github.com/andrejbauer/tt allows it.
I think I am confused about something. I am having trouble seeing what problems you run into with this kind of coherence, where you have no path constructors. Perhaps I need to play with code.
Yes! Play with code! Prove me wrong! (-:
Some more questions/ideas:
Would it be possible/desirable to include a proof that the judgmental equalities you choose give rise to a strongly normalizing type theory, and write the normalizer, and then always coerce along the path that the normalizer gives you? Or will you then need to prove that all paths given by the normalizer are coherent?
What diagram(s) have to commute for an equality to be fully coherent with another one? More concretely, for example, what property would I need to prove to be allowed to have
(Cᵒᵖ → Dᵒᵖ) ≡ (C → D)ᵒᵖ? (Alternatively, I’m asking for more explanation of how to carry out this procedure.)Keep in mind that nothing I’ve said here is very precise. But that said, my intuition is that yes, you would have to prove that the paths given by the normalizer are coherent. And by “fully coherent” I mean that all diagrams commute. It’s possible that some smaller subset of diagrams would suffice for this, but I have no intuition about that.
Nice post!
I’ve also been thinking about semi-simplicial types for some time. Nicolai Kraus and I are currently working on a paper that uses them, and the inability to define the universe of Reedy fibrant semi-simplicial types forces us to formulate and prove all our results metatheoretically, which is not ideal.
Assuming for a moment that the definition of such universe is indeed impossible to give internally, do you see any problem in just adding some syntax into the theory that allows us to talk about (finite) Reedy limits internally?
Essentially, fix any direct category structure on the natural numbers, and suppose given a fibration:
P : (n : Nat) -> M n -> Type
Where the type M : Nat -> Type represents the “matching object” of the corresponding Reedy fibrant presheaf up to n. Suppose M is automatically inserted into the context by the system, and is equipped with a _strict_ functorial structure. The system would then be able to give you the Reedy limit of the whole presheaf.
The consistency of such a system is not problematic, since any model of HoTT with omega Reedy limits (e.g. the standard model) admits this operation. I’m not sure how that would work in terms of decidability of type checking, but I don’t think there should be any problem in principle.
Maybe it’s even possible to restrict ourselves to linear Reedy limits, and somehow obtain the more general case from that. In any case, this looks much tamer than adding judgmental equality to the language.
What do you think?
I’ve also thought a bit about whether type theory could be extended to include infinite structures as “basic”, but haven’t really gotten anywhere. Your idea is intriguing, but I’d need to see more details, e.g. what do you mean by “matching object” and “automatically inserted into the context” and “able to give you”, and what rules would this construction satisfy that guarantee it to behave the way we want?
You are wading into deeply *syntactical* territory here. This is quite important to understand well, as it forms the basis of all computer algebra systems. Bill Farmer has been investigating the issues surrounding type theories which have reasonable features for dealing with syntax for quite some time. In particular, see
He also has a paper “Simple Type Theory with Undefinedness, Quotation, and Evaluation” which should appear as a Tech Report any day now.
One point you do not make is that, in mathematics, one sometimes wishes to make sentences of the kind ‘The statement S has no meaning’; the most obvious such S is , but other, more complex examples abound. Of course 1/0 should be part of the *syntax* of mathematics, but if it is ‘too typed’, then it is impossible to talk about 1/0 at all.
, but other, more complex examples abound. Of course 1/0 should be part of the *syntax* of mathematics, but if it is ‘too typed’, then it is impossible to talk about 1/0 at all.
Thanks for the references! It doesn’t seem to me that your two links are quite what we need, since they are done in a set-theoretic metatheory, and also seem to be more interested in describing and using an interpretation of syntax rather than constructing such an interpretation. However, the title of the forthcoming paper you mention suggests that it might be more helpful; I look forward to seeing it!
I do think there are ways to make sense of undefinedness without recoursing to manipulations of syntax. For instance, you can just talk about partial functions. Similarly, I think Farmer overreaches in his claim that differentiation rules must be understood as functions on syntax: that’s certainly true when you’re writing a computer program that does symbolic calculus, but not as a matter of pure mathematics. However, the basic point in both cases is a good one.
Sorry, I think I didn’t fully explain what I meant there. Of course, if inversion is a partial function in the sense of a function defined on a subset of the domain, then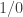 is not an object of mathematics about which you can make a statement like “it is undefined”. However, a partial function
is not an object of mathematics about which you can make a statement like “it is undefined”. However, a partial function 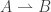 can equivalently be understood as a total function
can equivalently be understood as a total function 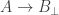 , where
, where 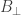 is the partial map classifier. In this case
is the partial map classifier. In this case 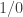 is a perfectly good element of
is a perfectly good element of 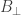 , and “being undefined” means that it is not in the image of the inclusion
, and “being undefined” means that it is not in the image of the inclusion 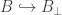 .
.
1/0 is too easy. You can make the game more fun. For example, what function is $\lambda x. 1/(1/(x-x))$ ? The only choices are ‘everywhere undefined’ or ‘everywhere 0’, but of which are justifiable (in different background theories). This is yet another source of non-trivial difficulties in the theory of symbolic computation.
It absolutely makes sense to talk of undefinedness without recoursing to syntax — and Bill has done that in previous papers. He has written many papers about ways to deal with partial functions, including some interesting studies of what people ‘de facto’ do, as opposed to only trying to create new formalisms to deal with it.
When he talks about differentiation rules, he’s really talking about ‘rewrite rules’ as they are used in symbolic computation systems, explicitly to contract them to the usual semantics of differentiation on functions. The basic point is that the ‘rewrite rules’ do not know anything about the semantics, and thus can be applied when the semantics is undefined: Maple, Sage and Mathematica do it all the time. This is just one source of nasty bugs in all these systems.
Thomas Streciher has worked on type theory with [quote](http://lists.seas.upenn.edu/pipermail/types-list/2006/001088.html) I seem to recall a paper after that exchange, but cannot find it currently.
Wait, so you’re saying no one has ever managed to convert well-typed first-order syntax (of a dependent type system) to inductive-inductive syntax, internally to type theory? Because if they have, I don’t see how the presence of higher h-levels gets in the way, and you win.
Actually, I think Conor McBride has — see his Levitation paper, as well as the Outrageous but Meaningful Coincidences paper. But you’ll see that it’s not that simple… Those two papers are real gems, I won’t spoil the surprise here, go read them.
I actually have. That’s why I don’t understand what went wrong.
I guess I should reread them and try to get it working.
I was actually kind of hoping that someone would turn up and say “wait, so-and-so has already done that…”, but no one has yet. Even if they did, though, we might not immediately be golden. For instance, they might have added a constructor to their inductive-inductive syntax asserting that the coercions of a given term along any two parallel judgmental equalities are equal. They might also have used UIP somewhere — conceivably without even noticing it, since if you don’t explicitly tell Agda --without-K then its pattern-matching is not homotopy-consistent.
As far as I can tell, Outrageous but Meaningful Coincidences does not solve the problem. He constructs an interpretation from well-typed syntax of his object theory (Kipling) to a certain inductive-recursive syntax in Agda; but the interpretation is not performed in Agda itself, but in the metatheory thereof. The interpretation is denoted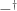 and
and 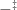 (p8), and he specifically says that it is an interpretation from Kipling syntax on paper to terms in Agda. I did not see a definition of the raw Kipling syntax as an inductive type in Agda or a definition of
(p8), and he specifically says that it is an interpretation from Kipling syntax on paper to terms in Agda. I did not see a definition of the raw Kipling syntax as an inductive type in Agda or a definition of 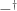 and
and 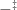 as functions in Agda. But I could be wrong or missing something.
as functions in Agda. But I could be wrong or missing something.
I just had a look at The gentle art of levitation, which I had not seen before, but I don’t think it helps either. It seems to be basically about encoding general inductive types as W-types, and then extending that encoding to the definitions of the structures involved in making sense of the W-types themselves.
Hmm, I just assumed–when I read “Outrageous…”–that it could be adapted to an IR definition of the meaning of derivations (rather than types). This would handle equality explicitly, defeating the purpose for that paper, but (or so I thought) making it easy to convert to via induction on typing derivations.
Like I said, I should probably just try it.
I don’t actually see why you’d need to jump through so many hoops though, to define semi-simplicial types. I saw your explanation, but I’m very new to higher-category theory so I didn’t try to understand it.
While I’m revealing my ignorance, is it possible to explain quickly why semi-simplicial types are so important? I would’ve thought they had something to do with the simplicial set model of HoTT, but I thought simplicial sets are functors.
semisimplical types would be nice for a bunch of things, and are already familiar to many who have played with homotopy. A roughly-equivalent problem is to define a type of coherently-commuting cubical diagram — semi-simplicial types have a sequence of underlying commuting cubical diagrams whose arrows and coherences have extra coincidences between them; but at the same time, any diagram with any desired collection of coherences itself encodes a particular semi-simplicial type whose realization is the (homotopy-)colimit of that diagram. Not having semi-simplicial sets (which is the same as not being able, in a generic way, to say “coherence in a diagram”) means that there’s a lot of structure in the homotopical category
Typethat we’re not able to talk about in HoTT. We can do the next-best thing and talk about n-coherence for any fixed n.For myself I’d like to be able to simply say “a coherently-commuting 0-cubical diagram is an object; a coherently-commuting (n+1)-cubical diagram is an n-natural transformation of n-cubical diagrams.” It’s that “n-natural transformation” bit that gets really icky!
I expect it can, but the definition would only be metatheoretic rather than inside of type theory. The point is to do it all internally. But yes, you should try it!
In my opinion, semi-simplicial types are just a particular case of what I call the “problem of infinite objects” (and in some sense the “generic case” since we expect that if we could do them, then we could do anything). In homotopy theory we often need to talk about structures that involve higher homotopy coherences in all dimensions. However, type theory only allows us to say finitely many things directly. We can talk about some infinite things, of course, like the natural numbers, by encoding them with finite data. But it seems that whenever you try to do this for infinite homotopy structures, you end up needing to already be able to talk about higher homotopy coherences in all dimensions to make sense of it. We don’t have a precise statement of why this happens or whether it is unavoidable; we’ve just observed “the same sort of thing” happening in lots of different situations.
“I expect it can, but the definition would only be metatheoretic rather than inside of type theory. The point is to do it all internally. But yes, you should try it!”
Right. “Outrageous…” coded it up in type theory, the modification would still keep it in type theory. We’d just be talking about something else, not talking somewhere else.
“In my opinion, semi-simplicial types are just a particular case of what I call the “problem of infinite objects” (and in some sense the “generic case” since we expect that if we could do them, then we could do anything). In homotopy theory we often need to talk about structures that involve higher homotopy coherences in all dimensions. However, type theory only allows us to say finitely many things directly.”
OK, I can buy that semisimplicial types are super handy for homotopy theory. But I don’t know homotopy theory; I’m working this from a type theory angle. I was hoping someone could give an explanation of how they would help model HoTT internally, but explain it without using advanced concepts from homotopy theory. I can understand if this is infeasible.
As for the “problem of infinite objects”, I’m very skeptical that there’s a real expressiveness gap here. I used to think intensional type theory was hopelessly restricted, and I spent hours trying to wrap my head around what the problem was, but really it’s just very inconvenient sometimes. I gradually learned a variety of tricks that can be used to make things work. The human mind is used to being able to work very flexibly, using meta arguments to justify novel forms of reasoning. ITT doesn’t allow this; it’s either well-typed or it’s not. Encodings from the way you think into ITT can get quite messy. In a theory like ETT you can use equality reflection to help, since essentially, well-typedness is now something you prove. But it’s been (metatheoretically) proven that ETT is a conservative extension of ITT + extensionality axioms.
Of course, talk is cheap. I’ll see what I can do about semisimiplicial types or interpreting first-order syntax.
BTW, how do you do block-quote, and other formatting here?
Use HTML: <blockquote>…</blockquote>
Thanks. Let’s see if this works…
Wonderful! That’s just what we need: more people with more different backgrounds and perspectives working on the problem.
It’s starting to look like it won’t work after all. When trying to interpret from typing derivations to the “Outrageous…” structures, there’s no obviously right interpreted context to use in the type of the interpreter itself, other to interpret the context syntax right there, which would be too circular for ITT, at least AFAIK.
But there’s some other loose ends I can finish up, and I might realize something. Another thing to try is making up some weaker requirement for the context, but then the substitution lemma might break.
I intend to say some more about this later, if I give up. For example, I may have to reinstate my old belief that ITT is hopelessly restricted.
I look forward to reading what you have to say!
Still working. Sorry about the suspense. This problem is tricky. But actually, things are looking up again. I found a plausible way to express the types of the interpretation functions. And I intuitively feel like the pieces should fit together. This just might happen!
On a slightly different topic, it’s looking like if this works, there’s actually the option of skipping an interpreter. I’m wondering about people’s opinions about whether the “ideal” development of these kinds of type families would go through an interpreter or not.
The nice thing about an interpreter is that it would centralize all the “Outrageous…” trickery into a reusable set of functions and theorems, so that developing a new messy type family would involve writing a generator for the syntax, and a proof that all generated types are well-formed.
Skipping an interpreter would make for technically simpler definitions, but each new family definition would need to work with “Outrageous…” structures instead of plain old syntax and type derivations.
Also, my current development is taking a short cut. It only deals with a subset of type theory which is sufficient to express semi-simplicial types. Primitive operations on semi-simplicial types will probably need a similar set of tricks to define, but the current development wouldn’t support that yet. But if the current development succeeds for the reason I think, I should be able to apply the trick to larger subsets of the type theory. Of course I can’t interpret the whole type theory, because of size issues, and developing a large chunk of it would be a lot of work, so another question I have for you all is what’s the smallest subset you foresee a need for. The above choice of interpreter or no interpreter would apply in any case.
Don’t be shy! Remember, I’m not the one who wanted these things. I need to know what I’m aiming for.
In general, I think we should explore all options: it would be nice to see it done both with an interpreter and without. But at first, I would be inclined to keep the interpreter, since it explains where the definitions come from and ought to be useful for other things. If and when you have something that works at all, then we can talk about adding more stuff to it; the philosophical reasons I mentioned in the post argue that eventually we should include the whole type theory (except for having one fewer universe), although once it’s clear that the idea works it may not be necessary to actually formalize the whole thing.
That makes sense.
Yeah, I guess if you go the interpreter way that’s only natural.
Just… How many universes is one fewer than infinity?
Coq has one universe per natural number; it should be able to interpret a subset with any finite number of universes. But more universes means more code duplication, since you can’t express the universe interpretation generically.
Right. Just getting the questions out there. No one has to do anything if it seems too speculative.
In practice we rarely need more than two or three universes, so I’d be pretty happy with an interpretation including that many, especially if it were done in a way that would clearly generalize to arbitrarily many.
This proof is intricate. Lots of dependent types and auxiliary lemmas. But I’m making steady progress, and finding bugs to fix in my typing rules.
The basic idea which got me going again last post is to define the interpretation function as a relation, then prove it total on well-typed stuff. The computational content of the constructive totality proof includes an interpretation function. I don’t know if that’s reassuring or enlightening or obvious or what, but that’s what’s going on. That is, I’m working on the totality proof; the relation is just the “Outrageous…” structures, but with an extra index for the raw syntax.
Mike, in your post, you said that in set theory you’d do metatheory of type theory by defining an initial algebra that you can build out of the syntax, and such that interpretations are the unique maps to other algebras. At least that’s how I interpreted that statement. Such an initial algebra seems like it’d be a lot like an inductive-inductive definition along with a map from well-typed raw syntax. What I’m getting at is that that seems to be the hard part. What’s the trick, and how would it be adapted to work inside type theory? Is it any less complex than an inductive-inductive definition like Chapman’s? I’m trying to get a sense of whether there are actually multiple ways to do this, or if they’re all essentially the same.
Interesting! I don’t immediately see why defining the interpretation function as a relation and then proving it to be total would be any easier than defining it directly, but I look forward to seeing what you come up with.
In set theory, you can construct an initial algebra in two ways. Firstly, you can prove its existence by general category-theoretic machinery; this yields an initial algebra by definition, but doesn’t tell you very much about what it looks like. In type theory, this corresponds fairly closely to an inductive-inductive definition (modulo problems of h-level). Secondly, you can construct an algebra out of raw syntax; this has the nice explicit description that we want, but is not obviously initial; one has to prove it to be initial by an involved induction (I would say this is the “hard part”). Once you’ve done both of them, of course, it follows that they are isomorphic. Alternatively, if you could show directly that they were isomorphic, then it would follow that the algebra built from raw syntax was initial, but generally that’s no easier than showing it to be initial directly.
I would say the “trick” involved in the “hard part” in set theory is that there, the algebraic structure in question is set-level, and we can strictify the desired semantics to also be set-level. (See the second paragraph under “Why I should have known it wouldn’t work”.) We can’t do that in (homotopy) type theory — the universe is not a set — so I don’t think this method can be adapted in any direct way.
It cleanly solves the problem I ran into, which was that I didn’t know what type the interpretation function should have. It should take the syntax it’s interpreting, including a derivation that it’s well-typed in some syntactic context. But it should also take an environment/valuation for the context, so that it can handle variables. But what type does a usable environment have? I.e., what is the semantic context? We would like to interpret the syntactic context to express that type, but we haven’t even begun to write the interpreter yet! Coq doesn’t have a way, like induction-induction or induction-recursion, to express that forward reference in the type. The fundamental difficulty is that we’re trying to mutually define the function and its domain. In set theory, that’s no problem; just build up the function as a relation in some order, and the domain is whatever it is. That’s what I’m imitating. Specifically define the interpreters for terms and types as relations, and then you can define the interpreter for contexts as a relation. Then we can say when things should be total: We’re interpreting some t that’s well-typed in context G, and G’ is “an” interpretation of G (really “the” interpretation, but we don’t need to care), so there should be some t’ that t interprets to in the semantic context G’. (t’ will be a function from environments of type G’ to whatever.)
Thank you for that clear description. The general category-theoretic machinery in question sounds important and useful. Can you give me a pointer to start reading about it? It seems like a way to construct something like an inductive-inductive definition in Coq.
Proving the initiality of the raw syntax seems like a good way to make the interpreter very reusable. So just knowing how to formalize the functor for which the syntax should be an initial algebra would be useful. Seems like with an initiality proof, you’d get some kind of induction principle for a whole language. Just the recursor would already be a generic interpretation function.
I can imagine! Just defining the recursor would have to be at least as hard as what I’m doing now.
Nope, sorry, I still don’t see what that has to do with anything. I can’t imagine what that trick is, or how it would help.
It sounds to me as though you haven’t even yet run into the problem that I was emphasizing in the above post, namely the need to prove infinitely many coherences mutually. That’s the problem which the “trick” of strictifying the semantics to be set-level deals with. Maybe you won’t ever run into my problem at all; that would be awesome!
I didn’t run into the problem you say you had of having to define a function and its domain. That might have had something to do with the fact that I was using Agda, which is more flexible with its induction and recursion, but I don’t think so. I was defining a function and its domain by mutual recursion, but I figured that could always be encoded as a single recursive function whose codomain was a sigma-type like . Is there a reason that doesn’t work?
. Is there a reason that doesn’t work?
The general category-theoretic machinery goes by names like essentially algebraic theories or locally presentable categories. The point is that if you have a category whose objects are defined in a certain syntactic way, namely as a family of sets together with certain partially defined operations satisfying axioms, then you can reinterpret them as set-valued diagrams on some small category that preserve certain finite limits. The category of such diagrams can then be proven, by general nonsense, to be a reflective subcategory of the category of all diagrams; so that in particular, it is cocomplete, and in very particular, it has an initial object.
Right. I’m not even sure what that problem would formally look like in type theory. I’ll let you know if I hit a major obstacle, and you can tell me if it’s the problem you were talking about.
Well so for interpreting types, say, you want to do induction on derivations of well-formed types, and a component of your domain is a semantic context, which is interpreted by induction on derivations of well-formed contexts. Those are different inductive types. Interpreting terms also needs interpreted contexts in the domain. So I’m not saying it can’t be done, but it’s not at all clear to me how you’d get everything you need all at once by computing a sigma with one monster induction.
The nice thing about the interpreter stated as several relations is that they’re quite similar to the typing judgements, so it’s relatively intuitive what I can do with them.
Thanks.
That’s certainly a point, but I thought you could deal with it because every well-formed type is in a well-formed context, and similarly every well-formed term belongs to a well-formed type. So, for instance, you could define by induction on well-formed contexts their interpretation
their interpretation  together with a function from well-formed types-in-context-
together with a function from well-formed types-in-context- to type families over
to type families over  , and then do an inner induction over well-formed types when defining the latter function in the inductive clauses of the outer one.
, and then do an inner induction over well-formed types when defining the latter function in the inductive clauses of the outer one.
This makes me wonder, though: is there a general theory of mutually recursive functions whose types are mutually interdependent? Agda allows all sorts of things like this that I’m not sure how you could translate into ordinary recursion.
Mike, have you seen very dependent types or insanely dependent types? The idea is that the type of your function can mention its own body, and you could do something like defining
Sigma A B = (f : (x : Bool) -> if x then A else B (f true)).Hmm, I guess those are similar. I had seen them before but didn’t think of them in this connection. Do they have a categorical semantics?
The two links that I listed are all that I know of the topic, but if you (or someone else) finds a categorical semantics, I’d be interested to hear of it.
I think very/insanely dependent types can already be constructed, possibly with the help of IR definitions.
Let a finite telescope be some left associated finite chain of sigmas. You can already define a type of codes for such telescopes, either with induction-recursion, or with a plain old inductive type in the next higher universe. Either way, you have a decoder function which gets you back the actual telescope, which is a type. This was one of the tricks in “Outrageous…”. (I’m using finite telescopes as semantic contexts in my interpreter. Just like that paper.) The next “Outrageous…” trick is strongly typed de Bruijn indexes, which tell you one of the types from a telescope, as a function of the telescope before it. Given an element of a telescope (an environment) and a strongly typed index, you can get the value of the indicated type out of the environment. Notice that this telescope projection operation is very dependently typed, but only for finite “dependency levels”.
To extend the situation to transfinite levels, use the decoding of telescopes as the types in a telescope, and cook up the appropriate strongly typed “de Bruijn ordinals”. This should be pretty easy with induction-recursion. It might burn up universes too fast without it, but I’m not sure. Generalizing to other well-founded (not linear) telescopes should work too (I guess at some point they stopped being telescopes.)
What I’m trying to say is that because very dependent types are required to have a well-founded relation between the function inputs to avoid circular dependency, they can be constructed as the generalized telescopes I described. The argument type along with the WF relation and very dependent family should be enough to use an argument as a strongly typed generalized index. The functions themselves are the generalized environments, and application is environment projection.
I briefly looked at the insanely dependent function link. It just looks like a very dependent function with a finite telescope for an argument type.
So very/insanely dependent types seem at most as bad as induction-recursion. And above I was trying to express my impression that aside from size issues, I don’t think induction-recursion is really all that new. It’s just defining codes for some subset.
I would be a bit surprised if you could do this in Agda already, though happy to see it. Note that in an insanely dependent function, all of the arguments are in a mutually recursive block; any argument’s type can mention itself and/or any other argument. Can you do this with telescopes?
Oh, no I didn’t realize that. I don’t know how you’d do that.
I’m guessing that by “finite left-associated telescopes” you’re referring to the type Cx defined on page 4 of “Outrageous”, that the “strongly typed de Brujin indices” are the variables defined at the bottom of page 4, and that the “projection” operation is the function
defined at the bottom of page 4, and that the “projection” operation is the function  defined at the top of page 5. But I don’t understand in what sense the latter is very dependently typed; can you explain?
defined at the top of page 5. But I don’t understand in what sense the latter is very dependently typed; can you explain?
I’m not sure which comment you’re referring to by “above”, but I have heard it said that aside from size issues, at least in extensional type theory induction-recursion with a fixed output type can be mimicked by an inductive family over that output type. That’s not really the same as a “subset”, but maybe it’s what you’re referring to? I’m not sure what the status of this is in intensional/homotopy type theory. But Agda also allows inductive-recursive definitions where the output of the recursive function is also one of the types being defined inductively as part of the mutual IR definition, and I don’t know how you would reduce those to inductive families (although in some cases you might be able to reduce them to inductive-inductive families).
I replied at a lower tab level because of these margins. Please scroll to the bottom.
It sounds like you’d get too many cases that way. I dunno maybe it’d work. You can try to figure it out if you’re really curious, but I’m sticking to the interpretation relations. There are ways to formulate all the rules of type theory in one judgement. The pure type system style judgement might let you interpret a context, type, and term at once. But from a computational point of view, it’s weird. You don’t actually want the context around at run time. You just need to talk about it for typing reasons. If you read spitters’ comment and my reply below, it looks like what I’m doing might be an example of a known technique for separating the computational content from irrelevant proofs.
As far as Agda allowing all sorts of mutual definitions, I think of induction-recursion as a type theory analogue of Gödel’s reflection theorem. But unlike ZF, it makes predicative type theory much stronger. I don’t understand induction-induction much, but it looks like Google is your friend. The results make it look like II is the tricky part, so a combination of II and IR might not be much worse. But I’m not sure, it could just be that Agda errs on the side of flexibility.
I’m mostly taking the point of view that I’ll first try to do it using anything that’ll work, and then worry about reducing it back to the core theory. (I also don’t quite know what “run time” means for dependent type theory, and I couldn’t make heads or tails of your exchange with Bas. (-:) And I’m familiar with II and IR (homotopically, I think IR is trickier to make sense of than II), but I think this is more than those, more along the lines of what Jason mentioned.
By run time, I roughly meant what happens in an OCaml program that you extract from Coq. But what I’d really like to mean is whatever you choose not to “erase”, where erasure is a way to “implement” something by throwing it out. It’s kind of like (strict) propositional truncation. Nuprl is great at controlling which parts of a development are erased, and which are “really there” at “run time”. Coq is quite a bit less great at it, but the Bove-Capretta method helps a lot.
I think I see now that what I was proposing wouldn’t work; you get the wrong inductive hypotheses. Maybe defining a relation and then proving it total is the best way to do it.
I haven’t followed the details, but the use of relations is crucial in the Bove-Capretta method.
Oh yeah, ad-hoc predicates! Now that you remind me, I was thinking about whether what I’m doing is an instance of that. I don’t think they’re quite the same in general. The intro to a Bove-Capretta paper that Google turned up says induction-recursion can be used if the domain and function are interdependent, but I actually knew for a while that you can instead just define the whole thing as a relation first in that case. The whole general idea of working with relations reminds me of logic programming.
The main difference I see is that with ad-hoc predicates, the main problem is that the intended computation to define is partial, whereas I’d say the main problem for an interpretation function is that the intended computation is not even necessarily well-typed! But in ITT, these are really the same problem I guess.
At the moment, the interpretation function I’m defining does not successfully separate the ad-hoc interpretation relation from the computation, and it’s already hard enough. Maybe if I succeed with what I’m doing now, it’ll turn out there’s a way to banish the interpretation relation, like with ad-hoc predicates. But even then, the typing derivation is still there, and it’s currently what I do induction on. Actually, I guess I should try to put both relations in Prop, do recursion on terms, and inversion on the interpretation relation to blow away bad situations. But HoTT doesn’t use Prop… IMHO, HoTT is going to need some way of using strict propositions before it’ll be useful for serious programming. (Of course it also needs a good computational interpretation for a lot of stuff.)
I guess what I’m saying is that with any luck, this can indeed by viewed as roughly the Bove-Capretta method; a rather involved instance.
(In response to Mike’s comment)
Yup, that’s what I’m talking about. How do I quote you without ruining your math symbols?
Sure, I should’ve done that already. Oops.
Since you can project out any type in the context from an environment, an environment is equal (definitionally, I believe) to a left associated tuple of projections. The type of each projection is some (arbitrary) function of the tuple before it. In other words, the type of a projection is a function of earlier projections. This is what very dependent function types give you.
You’d have to re-insert the math delimeters around the latex code.
I see that each environment is equal to a left-associated tuple of the previous projections, but the equality doesn’t look judgmental to me; don’t you need to destruct an element of Cx in order to turn it into a tuple?
But I do think I see now how you’re saying you can use this idea to mimic a very-dependent function whose domain is a finite type with a total well-founded order. We define inductive-recursively the type VDF(n,B) of “codes for very-dependent functions” with domain Fin(n) and a given “codomain expression” B[x,f] (depending on both the input x and the function f itself), along with an interpretation function sending a code for the very-dependent function g to the type B[suc(n),g] that should be the output type of an extension of g to a very-dependent function with one larger domain. The definition of VDF(n,B) has two constructors: one for the unique very-dependent function with empty domain, and another saying that if g has domain Fin(n), then to extend it to a very-dependent function with domain Fin(suc(n)) we just have to give an element of
sending a code for the very-dependent function g to the type B[suc(n),g] that should be the output type of an extension of g to a very-dependent function with one larger domain. The definition of VDF(n,B) has two constructors: one for the unique very-dependent function with empty domain, and another saying that if g has domain Fin(n), then to extend it to a very-dependent function with domain Fin(suc(n)) we just have to give an element of  . And the definition of
. And the definition of  is just where we put in the expression B[x,f]. Finally, the “Outrageous” inductive definition of
is just where we put in the expression B[x,f]. Finally, the “Outrageous” inductive definition of  tells us what the possible output types of the application of a very-dependent function are, while the recursive definition of
tells us what the possible output types of the application of a very-dependent function are, while the recursive definition of  computes the actual result of such an application. Is that right?
computes the actual result of such an application. Is that right?
I don’t yet see how to extend this to other well-founded relations, though. The definition of the type of function codes (corresponding to the “Outrageous” type Cx) is by cases for “empty” and “successor”, but elements of general well-founded relations don’t bifurcate in that way. In classical logic, transitive well-founded relations (ordinals) trifurcate into empty, successor, and “limit”, but constructively even that isn’t true.
I’m not talking about equality on elements of
Cx. Those are the codes for contexts. I’m talking the elements of the actual semantic contexts, which are the big nested sigma types. Those elements are already tuples. The equality should be definitional because you’re just computing down to g from a tuple made out of all projections of g. (“g” is a canonical element of the semantic context.) Proving that they would be equal for an arbitrary context would of course not be definitional, but for any given context, the equality in question for any canonical environment of that context is definitional. But yeah, I guess when you work out the details, it’s not so important that this case works out definitionally.I’m not going to check your construction in detail. Agda can do that better than I ever could. I don’t think it’s quite what I had in mind, but it’s similar. I think you get the idea.
I still think it would extend to other well-founded relations. You know about the
Acc“accessible” family for well-founded induction, right? I think you could use that as codes for an arbitrary well-founded relation. But I don’t think you’d want to. Any specific sensible WFR will probably have a more natural construction for codes. AFAICT the constructivist POV is that “well-founded” is a bad word for “inductive”. I wasn’t trying to get at specific constructions, just the general plan of attack. The example with ordinals was just to argue that we are not fundamentally limited to finite dependency depth.This topic is interesting, but I’d better not think about it too much. I’m supposed to be doing an interpreter. 🙂
I don’t see how Acc helps. But sure, let’s not spend forever on this.
I do think well-founded relations are a perfectly sensible constructive thing to talk about. Certainly sometimes a well-founded induction is better regarded as an induction over a particular inductive definition, but I think there are plenty of situations where you want to induct over a well-founded relation that isn’t the “subterm” relation of an inductive type (hence the introduction of Acc to make it into one). Coq even includes a lot of support for functions defined by such well-founded induction.
(In response to Mike’s comment)
My bad, I got confused. The comment was actually below that one, although I posted it earlier. But don’t worry about it, I probably spoke too soon.
That’s probably what I was thinking of. An inductive family is at least as good as a subset in this case. The subset is the image of decoding the family back into its index type. And of course with IR, the decoder is given directly.
Yeah I don’t know about all that. There probably is more to it than I realized.
I hit a tricky part. I’m trying to define weakening on the interpretation of a judgement. For weakening at the near end of the context, it’s easy, but I haven’t figured out how to weaken in the middle yet. I know how to express the requirement, but I’m having a hard time proving it can be done. It’s weird, you’d think this would be a no-brainer. Maybe this is related to the coherence problem you were talking about?
Since weakening is a special case of substitution, it probably is related.
I figured that part out.
I also realized I probably didn’t need to do it.
After a great deal of mucking about and learning some things that one cannot do, I think I found the right way to express structural operations on semantic contexts so as to prove that they are respected by interpretation. And I think I might be starting to understand the coherence problem you were talking about. I read about coherence theorems on nLab. I didn’t understand the details, but the gist of it seems kind of like the issues I had to find my way around. Here’s what I’m thinking:
First of all, the “Outrageous…” structures need a better name. I’d like to call them “handles” because they give you concrete structures to handle the abstract results of interpretation. Aside from allowing us to refer to interpreted contexts before we have an interpretation function for that, we can use handles to keep track of other important properties of semantic contexts that we’re passing down an induction.
The handle for structural operations is simple:
ExtCtx GL n Gsays that G is the resulting of adding n entries to the near end of GL. At least that’s what it says as a relation. Given a proof of this, it makes sense to weaken a judgement by adding a new entry between GL and the rest of G, for example. An element of theExtCtx GL n Gtype actually tells you what entries were added to GL to get G. This is important because you can’t take apart G to find them. I knew this, but I kept hitting dead ends because I failed to intuit all the consequences of this.I used to be using a handle with more indexes, because it looked like the handle type alone, and an arbitrary instance, told me enough to push through the proof that interpretation respects weakening. But it turned out I needed to show that two corresponding intermediate entries were equal. I couldn’t conclude this just from the indexes because they were formed from the intermediate entries, and we don’t know the formation is injective. I tried proving it by induction on the arbitrary handle, but I decided that the lemma I needed for that was not provable; I forget why not. Another problem with the handle with more indexes that I ran into more recently is that it actually says too much to easily move to an arbitrary subexpression. I could probably fix that with a lemma, but it’s really the wrong approach.
It seems that to prove that interpretation respects weakening, you have no choice but to reason about specific proofs of
ExtCtx. By that I mean that one should think ofExtCtxas a dependently typed data structure with operations, not a relation with lemmas. AnExtCtxwe get out of a certain operation will have properties that an arbitrary element would not. The thing that this might have to do with coherence is that:In general to reason about specific values, you want equations. The
ExtCtxhandles for semantic contexts have at least as much going on as the underlying semantic contexts, and thus can be of any dimension, and involve arbitrary types with arbitrary paths, so an equation onExtCtxs seems like a commuting diagram, or something about as bad.We only get to play this game using handles, since we know practically nothing about the codomain of the interpretation. This seems kind of like the issue mentioned on “coherence theorem” that commuting diagram coherence only works on freely generated stuff. The handles are free somethingorothers.
The old handle family with too many indexes had some nontrivial proofs of equations, but the new simpler one actually doesn’t yet. The equation I have for it so far works out definitionally. But I’m expecting a more interesting one soon to prove that indexing a weakened context with a variable is the same as weakening the result of indexing the original context.
So after a bunch of time spent investigating wrong ways to express weakening, I seem to be making progress again with operations and equations on context handles. Equations for other families of handles makes sense too, but I haven’t needed them yet. Hopefully I won’t need them because they’re a pain in the butt. Once you understand the handle family as a data structure, they’re intuitively obvious and require no cleverness, but you still have to write a bunch of garbage to make them type check.
So how about my explanation of coherence? Is it coherent? 😉 Am I addressing the same problem you had yet? Did I solve it? I’m more confident that I’m making progress on the formal proof than I am that I understand what it has to do with coherence. 🙂
I hit what looks like a big problem. The handle for weakening and the one for indexing with a variable both come up as variables currently, so I’d probably have another problem proving they’re dealing with the same context entries. I could try to add more constraints to say that it all comes from the master context interpretation handle, but that’s starting to sound like the higher coherence infinite regress you were talking about.
I have some ideas, but I’d like to know your thoughts about what this has to do with the coherence problem first.
Thanks.
It’s hard for me to tell exactly from your description, but my guess is that you’re hitting the same issue. The point that “to reason about specific values, you want equations” does sound like the point of a coherence theorem: when you keep track of morphisms and higher morphisms, you need laws relating those morphisms in order to do anything useful.
I’m relieved to hear that. At least I’m not completely confused.
Although it may not be necessary, I feel like I should apologize for my premature confidence that I could do this. I didn’t really understand the situation well enough to even be confident it was possible, and it might have seemed insulting that I believed I could do what you gave up on. I did not mean to be insulting or superior, and I regret that it may have even come across that way.
I now suspect that a full interpreter, and maybe even just semi-simplicial types, are not definable in ITT. My construction of very dependent also does not seem to extend to transfinite dependency levels. (At least not in ITT.)
I wonder if there’s a deep reason for this. I suspect that an interpreter for, e.g, HTS (where you get a type of strict equality), can be defined within HTS, at least if you have the analogue of higher induction recursion for strict equality constructors. I am also only a little surprised at the success of Martin Escardo at autophagia when you remove definitional equality from the language all-together (I wonder, though, can that construction still be done if your ambient syntax/language has only explicit casts and no definitional equality?). I wonder if there’s some deep incomparability theorem about type theories with types for strict equality and those without it.
I agree, I also suspect you could (modulo size issues). You might not even need induction recursion, as long as you have inductive families with strict indexes, since the problem I seem to be running into is the same kind of coherence problem as Mike talked about, even though I only used inductive families. The lack of IR doesn’t seem to be a problem here.
I think there is a deep reason for the trouble we’ve had. The fact that ITT has strong normalization seems to create an impenetrable separation between proofs and derivations. You can’t interpret raw syntax because you don’t know it’s well typed at the judgement level, and a proof inside the system cannot help, because the result has to actually be (judgmentally) well typed. Equality reflection directly breaks this separation, and it also breaks strong normalization. Of course that’s not a proof of anything, but it summarizes my intuition. I’m currently thinking about how this intuition could be made precise and hopefully proven. I’m gonna say more thoughts along this line in another comment below.
That does look interesting. Gonna read it soon. I wonder if they’re using explicit substitution and weakening. My interpreter wasn’t going to have definitional equality either (since semi-simplicial types don’t need reduction), but I still got stuck on implicit weakening. Maybe if you get rid of everything interesting from the judgements it works, but I’m still surprised.
Your intuition for a “deep reason” is really interesting! I hope you can make it precise somehow. Some of us have wondered idly whether there could be a semantic argument for such an impossibility, e.g. a categorical model in which the type of semisimplicial types doesn’t exist, but never had any ideas about how to construct such a thing.
Oh I see, Autophagia uses inductive-inductive syntax. I’m not so surprised anymore. Elements of inductive-inductive types can already have arbitrarily many dependency levels in play, so evidently you can rearrange them a bit to get an interpretation. Not so with a raw syntax interpreter or semi-simplicial types, where arbitrarily many dependency levels need to be built up from the ground. It’s that last part that seems like the problem.
Thanks for your apology, but I don’t think it’s necessary. I am by no means an expert in type theory, and I still think (and hope) it’s possible that there is just some trick that I/we are not seeing that will make it work. The reason I made this post was precisely in an attempt to get people like you to try it! (To be honest, it took a bit of courage to write the post for that reason, knowing that someone might turn up and explain that what I thought was a hard problem was actually easy.) The fact that you seem to be running up against the same problems I did, even though you’re coming from a very different background, partly confirms my feeling that there’s something deep going on that we don’t fully understand.
Well I’ve read some of your earlier posts, and from that and our communication so far you seem pretty far along now. At least I was impressed.
But also there are other type theorists who presumably read your post who I’m sure have more experience than me, and they didn’t rush in with a solution.
Just sayin’…
Well, I’m certainly not a clueless newbie any more. I learned a lot from the type theorists at IAS last year, and I’m a lot better now at “talking like a type theorist”. (-:
Here are some of my favorite thoughts regarding my intuition that a interpreter and maybe semi-simplicial types won’t work in ITT + axioms, or at the very least, won’t work well. I try to back most of these up informally, but I have no results.
Strong Normalization
The last idea I had before I changed my mind and decided an interpreter for a dependent type wouldn’t work in ITT was to propositionally truncate the handles. I figured this would get rid of the coherence problems, but create the problem of obtaining the interpretation after I prove it exists. I figured the Bove-Capretta method would let me do that, since the idea there is to define a function that doesn’t computationally depend on proof, but needs it to satisfy the type checker. But part of me couldn’t believe that would work, and that’s how I ended up thinking of strong normalization.
Because of strong normalization, I’m pretty sure the Bove-Capretta method cannot help with defining an interpretation function. If we could define an interpretation function that didn’t computationally depend on the proof of well-typedness, we could give it some false typing proof that we assumed, and interpret any old nonsense. In ETT, that’s to be expected; under false assumptions, the whole type system becomes trivial, not just which types are inhabited. But for the sake of strong normalization, things remain well typed in the usual way even under false assumptions. This means the only way you could have an interpreter is if it looks hard enough at the typing proof to make sure it isn’t “fake”. In other words, we cannot yet rule out an interpreter that would get stuck on fake proofs. But anyway, I conclude that trying to eliminate computational dependencies on the proof is not going to work.
For me, this is already reason enough to prefer ETT (in the expanded sense of any dependent type system with some ETT-like reflection of judgmental equality). From a computational point of view, an interpreter is a program that turns raw terms into some corresponding object. (Or at least simulates the corresponding object, which is different under sequential evaluation.) Whether an object from the interpreter makes sense to your system depends on whether the term you interpreted was well typed, but that doesn’t matter to the running program. Only to the logical system reasoning about it. ETT naturally separates the computational stuff from the logical stuff about it, whereas in ITT they get all mixed up in general, necessitating ad-hoc extraction mechanisms to finally throw out what should’ve been separate all along. Yeah yeah, constructive logic, PAT… You can do that in ETT. But in ITT, it seems that sometimes you can’t help but run the computational interpretation of your proof, even if you don’t want to. In particular, any interpreter for dependent type systems definable in ITT is going to run much more slowly than it ought to, as it looks through the typing proof and somehow turns it into handles or codes to ultimately compute something relatively simple.
Anyway, I did try Bove-Capretta anyway, and indeed I needed something that I couldn’t get by interpreting subterms. It would’ve had to have ultimately come from the typing proof. So it really doesn’t look like propositional truncation is an option. Although I don’t have as good an intuitive argument for it, it seems like no axiom can help because the interpreter would just get stuck on the axiom variable when you try to run it. This is part of the intuition of a separation between propositional facts and judgmental facts. An interpreter in ITT needs judgmental facts to run, and axioms do not provide any judgmental facts.
Dependency Levels
I said I suspect there’s no interpreter at all in ITT, but so far I’ve only argued that it would not use axioms, and would slowly mess around with proofs. The other main ingredient of my intuition why it won’t work has to do with dependency levels.
By the dependency level of a term, I roughly mean how many times did the type of one subterm depend on another subterm. My intuition about it is as a semantic property, but I seem to remember it being formalized as a syntactic property. (I’ll have to check.)
A dependently typed language has terms with any number of dependency levels. Otherwise it’s a “stratified” type system, though it may be presented using the framework of dependent typing, like the PTS versions of System F or HOL. So semantically speaking, an interpreter for a dependent type system should have an infinite dependency level, since you’ll get out anything from a dependent type system from it.
Universes and some other types have an infinite dependency level in that they have elements with any dependency level, and that we do have in ITT. But it’s different from what we want in an interpretation function or a family of semi-simplicial types, where we plug in something with finite dependency and get out something with arbitrarily much dependency. Types may allow for dependency, but functions actually provide it. Or not. I don’t know of any examples of a definable function that builds up arbitrary levels of dependency from input with finite dependency. This sort of “dependency building” is what I’m hoping we can show doesn’t happen in ITT. If indeed it doesn’t then we won’t be getting semi-simplicial types in ITT. At least not if they have to work out definitionally.
What if we added it as a primitive? Well I’m also wondering if maybe dependency building is sufficient to get equality reflection. Dependency levels certainly show up in an important way in typing judgements. So if my propositional/judgmental separation intuition is right, dependency building is a particularly severe form of getting judgement-level structure from nowhere. Since it couldn’t possibly have come from a mere proof that it makes sense, right? 😉 That’s ETT’s job.
No Dependency Building
If my “no dependency building” intuition is right, interpreters for stratified systems work in ITT because basically all the (finite) dependency is already in the interpreter, ready to instantiate. And interpreters of inductive-inductive “syntax” work because all the dependency you need to interpret a term is already in the inductive-inductive code for the term. No dependency building, just shuffling. What about very dependent functions? Well I don’t know how to make them work when the well-founded relation that describes the desired dependency has infinitely increasing chains. That would be dependency building. (And of course there are no infinitely decreasing chains, by definition.) I heard that the Nuprl team is phasing out very dependent functions in favor of intersections. Intersections to not provide dependency building, but that’s probably OK; it seems dependency building is no biggie in ETT. Does anyone know of dependency building working in ITT? (I remember Ulf’s insanely dependent functions. Adding it as primitive doesn’t count.)
My current plan for showing there’s no dependency building is to find that syntactic measure of dependency level, which is a natural number, and prove that it does not increase due to a step of reduction. I’m hoping the syntactic measure will make sense and nonincrease in ITT for the same kinds of reasons ITT has strong normalization, since they both seem to be about keeping the judgements clean of whatever’s going on in the proofs. So I’d try a logical relations proof. But I’d be really happy if someone with more paper-and-pencil metatheory experience worked it out first. For me it’d be another month or more of fighting Coq.
An easy corollary of that result would be that the semi-simplicial type family is not definable in ITT, because the family is a finite term, with a finite dependency level, and it’s given a nat with 0 dependency level, and it must somehow produce any dependency level you ask for. An interpretation of raw, dependently-typed terms cannot work either for a similar reason. The input has a typing proof, which brings the level up to 1, but the output is still any level.
(To be continued…)
Thanks for sharing this! I have a few questions. First of all, it never entered my mind that you could hope to define an interpreter that didn’t look at the proofs of well-typedness, since otherwise how could you possibly know how to build up the result of the interpretation. I don’t quite understand how you’re thinking that ETT would get around that; it seems to me that you would still be looking at the proofs, but you’d just get to stop the infinite regress after some finite point since the universe is a set.
Second, why does the fact that “things remain well typed in the usual way even under false assumptions” mean that “the only way you could have an interpreter is if it looks hard enough at the typing proof”? It’s true that if I work in a context with an assumption that some gibberish is a well-typed term, then my interpretation function is going to claim to give me some element that might not exist, but I don’t see how that’s any different from the fact that if we assume an element of False, then we have an element of False. Doesn’t strong normalization only apply to closed terms?
Third, you said that the universe has infinite dependency level, but then you seem to be saying that the type of semisimplicial types can’t exist because it has infinite dependency level. I guess I must not understand what you mean by “infinite dependency level”. Note that some “infinite structures” that look superficially similar to semisimplicial types are definable in ITT, such as the type of towers or the type of globular types; don’t those also have infinite dependency level?
What is the type of towers? Are globular types coinductive?
More concretely, do either of the following (or their variants where you replace with
with  , have infinite dependency?
, have infinite dependency?
forall/exists/Fixpoint rep (P : Type -> Type) (n : nat) : Type -> Type := match n with | 0 => P | S n' => let rep' := @rep P n' in fun (T : Type) => P (rep' T) end. Eval compute in rep (fun T => forall x : T, x = x) 2 Type. (* forall x : (forall x : (forall x : Type, x = x), x = x), x = x *) Fixpoint rep2 (P : forall T, T -> Type) (n : nat) : Type -> Type := match n with | 0 => fun T => forall x : T, P T x | S n' => let rep' := @rep2 P n' in fun (T : Type) => forall x : T, rep' (P T x) end. Eval compute in rep2 (fun T x => x = x) 2 Type. (* forall (x : Type) (x0 : x = x) (x1 : x0 = x0), x1 = x1 *)There is exactly one tower of height 0; a tower of height n+1 consists of a type A and an A-indexed family of towers of height n.
There is exactly one 0-globular type; an (n+1)-globular type consist of a type A and an (AxA)-indexed family of n-globular types.
Both could also be defined coinductively, but these definitions are just ordinary recursive.
So then…
Those don’t count as having infinite dependency level in either sense.
Jason’s
repandrep2are interesting. It seems like he may have caught me on a technicality, or maybe they really do help! I’ll have to think about that.Since all these examples can be written either as a recursive function or an inductive family, it makes me wonder if our problem is related to the inability to avoid storing indexes for an inductive family. (The recursive function version does not store the index.) Because of weak equality, storing the index may introduce spurious non-constructor elements.
Mike, you wrote about how in ITT not all maps are display maps, and that this has implications for inductive families. Might that be related?
Yes, those are what I meant.
In that case, I have no idea what you mean by infinite dependency level. What is it that distinguishes semisimplicial types from these two?
Really? After I put it up, I figured it can’t be right. Aren’t those just glorified units?
Yeah I’m gonna track down a definition of dependency level real soon now.
Oh wait, I see what’s going on, it stores the types too.
Yup, Jason’s
repfunctions are a great counterexample. Clearly dependency building isn’t hard enough to be what’s hard about semi-simplicial types or an interpreter. I’ll have to think some more, and this time I’ll try to find my own counterexamples.Anyone have any ideas about the issue of inductive families, display maps, and stored indexes, like I was talking about?
By the way, the dependency level definition I thought I read about wasn’t any such thing after all, so never mind dependency levels for now.
The fact that inductive types store the index is indeed related to the post of mine that you linked. (Although if you’re going to understand HoTT, you have to get rid of the idea that those extra elements are “spurious”.) I don’t immediately see how it’s related directly to this question, but it might be.
Well, what I was getting at is that I’ve been working with handles like
and I hadn’t initially realized that they are different from the inductive-recursive codes they ostensibly correspond to. The above family is equivalent to:
Where now the extra paths are explicit. What I really want is (fake Coq induction-recursion syntax):
This doesn’t seem to have any extra paths, and the decoded context isn’t stored. While I’m not sure this makes a difference in whether semi-simplicial types are definable, it looks like IR at least makes things simpler. If we can’t even seem to define dependent contexts without extra junk, an interpreter seems like a long shot. But I don’t know, that would seem to imply that Agda might do it but not Coq.
I need to experiment with handles some more.
Perhaps you would need to look at the proof in any homotopy compatible theory, or even regular ETT, but I suspect in Nuprl you wouldn’t need to compute with the proof. Nuprl’s semantics is Partial Equivalence Relations (PERs) of untyped terms. Everything you could do in, say, pure functional Lisp you could do in Nuprl; the problem is whether you can then assign it a type. But as a rule of thumb, you can assign it a type as long as it has the right behavior, since Nuprl has the subject expansion property (very unusual). I haven’t actually done a well-typed interpreter anywhere yet, but my ideal type theory would have to allow the proof to be erased at run time.
I understand that this may violate all mathematical intuition, and may be very difficult to reconcile with non-CS models of type theory, but having to compute with complex dependent typing proofs just doesn’t seem like what you really want. No implementation of dependent type systems really fully takes advantage of dependent typing for optimization, and I suspect none ever will. The dependent types get mostly erased by the time your program becomes optimized machine code. An interpreter then has no business keeping it around. There seems to be a mismatch between the properties you want for optimization and the structure that conventional dependent type theory provides. I hope I’m wrong about that, but I don’t see it.
I could tell you all about my current plans for turning type theory into a more practical programming system, but that’d be getting way off-topic. Suffice to say that it’s gonna be hard enough getting regular programmers to buy type theory even if we don’t leave in grievous performance issues.
I don’t even know how to write an interpretation function in pure functional Lisp. I don’t even know what that would mean.
I’m not talking about an “interpreter” in the usual sense of programming, as in a program which reads source code and normalizes it. I’m talking about an interpretation function which assigns to syntactic types and terms an interpretation that is a “real” type or term in the metatheory.
See the Wkipedia article for the basic idea of an interpreter from a programming point of view. Interpretation is not just symbolic execution or normalization; you do get something “real”, including real side effects in an imperative language. That article doesn’t discuss in detail how an interpreter is implemented though. Ignoring performance, it’s easy to implement in an untyped functional language. Lisp was a bad example, because it comes with an interpreter. Here’s an interpreter for the untyped lambda calculus, in vaguely Haskell-ish syntax:
Here, we’re using Church-style self-eliminator encodings of data types as higher-order functions. (Essentially the same as what you do in System F.) “t” is a quoted term, which we eliminate to handle variable, application, and abstraction terms. “i” is a de Bruijn index, a Church nat. “g” is an environment, a list of values to use for variables. Low indexes are to the left. “a” and “b” could be anything; they are the results of interpreting the subterms of an application. “d” is the body of a (quoted) lambda.
index g igets the ith element of g.While the term representations and the indexes could be adapted to System F or set-impredicative Coq, typing the rest is nearly impossible, but I’ve formally verified it by embedding the syntax and operational semantics of the lambda calculus in Coq. In many ways Nuprl is more like external program verification than conventional type theory is, which is why I believe it could assign a type to an
evalfunction like that, except using a predicative representation of data. Of course the type would only say what happens for well typed quoted terms, but that doesn’t factor into the program itself. The beautiful thing about Nuprl is that interpretation in the programming sense and in the logical sense are the same thing, but execution issues and soundness issues can be addressed separately.One of these days I need to try to understand Nuprl. Nothing that anyone says about it ever makes any sense to me, so if I sat down and understood it then maybe many things would suddenly become clear.
The margins are getting tight again. I replied below.
Do you mean, an interpreter written in NuPrl would be able to compute the term-in-the-universe without inspecting the well-typedness proof (and maybe even generate a term corresponding to its type), but proving that your interpretation function is well-typed (i.e., that it spits out valid terms and valid types) would require inspecting the well-typedness proof?
Yes, if I’m not mistaken. It turns quoted terms into objects without caring about type. This includes types themselves, provided you have the cases for them. Separately, you prove that the interpreter function has a type because when given a well typed term, it produces something with the interpretation of the type.
The quoted type and typing proof would appear in the type of the interpreter in erased positions: either the predicate of a subset type, or the domain of an intersection. Either should work since you can curry the arguments the way you can curry sigmas into pis.
In ITT and other strongly normalizing logical calculi, lies are different from nonsense. An assumed element of False is an outright lie, but it’s perfectly well typed. We can use it to abort any proof we want (False elim), and that just gives as a bunch of code that doesn’t do anything interesting. We can safely reduce it because it’ll get stuck on the abort of the false assumption. When we actually compile and run it, everything under the false assumption will be unreachable “dead” code.
A false assumption always gets dead code in that sense, because we’ll never be able to provide an element of False at run time. However…
No. In practice, the need to safely reduce open subterms is precisely the thing that makes strong normalization strong. In ITT, all you can do with lies is prove anything you want with abort, and you still normalize to “neutral” normal forms stuck on variables. But in ETT, for example, if you assume false, then you can prove that for all types T, T = T->False. Then you reflect that equality to make the omega combinator “well typed”, and you’ve got an infinite loop. The loop is still dead code, which is why ETT can be weakly normalizing (though Nuprl gives that up too for some types), but strong normalization is out the window.
So getting back to the interpreter, we don’t necessarily have equality reflection, but what if we assumed omega had type unit, then interpreted it to an element of unit? Provability wise, that’s the same as aborting a refutable assumption into unit, but it runs like an infinite loop, not like a neutral term.
How can we “assume omega has type unit”? The context is a list of variable declarations, i.e. assumed inhabitants of types, but “omega has type unit” is a judgment, not a type.
Yeah I said that sloppily because I thought, speaking of interpreters, you’d know what I meant.
You write down a raw term for omega (with any argument types you like, since we’re lying). Then you assume a typing proof saying that in the empty context omega has type unit. That’s all syntax, and we can do that in Coq. It’s because we are assuming we could then interpret it that we must’ve lost strong normalization.
But again, if the interpreter has to look at the proof, it gets stuck and we don’t necessarily lose strong normalization. I’m surprised that I seem to be the only one talking who considers ignoring proofs at run time to be totally expected and desirable.
Assuming what you're saying is true (which I'm not sure it is), I think it's because there are two barriers people here have to overcome to get to that point: (1) HoTT says that, by default, all proofs are (and should be) relevant for everything, and (2), in Coq and Agda, "ignoring proofs" is something that gets slapped on after the fact, and it's not obvious why it's a good thing, and it's not obvious that it's a thing that can always be done, and it's not something that plays any foundational role. (As a personal anecdote, I was very confused for a little while about discussions on when you can do type erasure at compilation time in Haskell; coming from the Coq world, compilation is "type inference + typechecking" and so my response was "well, you can erase the types when they're inferrable again, because otherwise you can't compile/type check".)
Yeah, what I was talking about seems to be more intuitive from a programming background. And the fact that proofs are often relevant in HoTT means that a computational interpretation for it will be quite different from any type theory implementations thus far.
Okay, I think I see what you’re proposing. We assume in the metatheory that omega has type unit, and in the metatheoretic context of that assumption we interpret it to some element of unit. But I still don’t understand how that is different from assuming an element of False, since the (metatheoretic) type of witnesses that “omega has type unit” is empty.
Maybe I’m just unable to wrap my head around the idea of what it would mean to have an interpretation function that “doesn’t look at the proof”. Are you saying that such a function would necessarily have to map the object-language-raw-term for omega to an actual “omega” in the metatheory? Why?
Yes, I shoud’ve said that.
Right, but it’s ignored, so we just run the interpreter on the raw term for omega and loop.
Yes, of course! What else could the standard interpretation of omega be? 🙂
It seems like you don’t have an intuition for untyped interpreters. In hindsight, it was foolish of me to bring this up now that I realize it’s so different from homotopy type theory. We don’t need to be talking about this, since it looks like you agree we shouldn’t have an interpreter in ITT that ignores the typing proof. But I’ll say more in reply to your comment about Nuprl.
The universe allows for any dependency level. (Syntactically, any dependency level is finite, I believe. I still need to check that, and put up what I hope I mean.) But it’s not dependency building because reduction isn’t even involved yet. It just gives you a place where you might build up dependency levels, if it’s possible.
Then don’t worry about it. Dependency building is the more precise issue.
I’ll take a look and tell you if they obviously allow dependency building. If they’re just individual types then it doesn’t matter that elements can have any dependency level.
Well, maybe then what I don’t understand is what you mean by “dependency building”. (-: Do you need a more precise definition of towers and globular types than what I gave above?
Was my Coq transcription correct?
(In response to Mike’s comment)
In the world of untyped programming–which purists sometimes call uni-typed programming–one still speaks of types. But they’re not an inseparable part of the language, they’re an overlay of specifications for untyped programs. It’s this notion of typing that Nuprl provides, with the exception that codes for types are part of the untyped language. It’s very different from typing in ITT or most typed programing languages. Usually, and what you are probably used to, a type is a place where you can construct an element. This is the notion of type system that corresponds to categories, where types are objects and terms in a context are morphisms. With that notion of type, it makes no sense to interpret something without its type. But when types are specifications for untyped programs, an interpreter makes sense already, before you’ve even put types on the table.
If you really want to understand Nuprl, you should first make sure you understand untyped programming. I would recommend you find some programming exercises in Scheme. But if that doesn’t sound like fun, then you probably wouldn’t like Nuprl anyway. At any rate, Robert Constable has been doing lectures on Nuprl every year at the Oregon Programming Languages Summer School for a while. That’s how I got into it. He never seems to give a systematic presentation of the system, but there’s the Nuprl reference manual appendix for that.
Mike, perhaps an example will be useful. If I understand correctly, when you are trying to interpret an application when typing is after-the-fact, you can say that the interpretation of App f x is ((interpret f) (interpret x)), and prove after-the-fact that (interpret f) is somthing that can be applied to (interpret x); you don’t need to transport across proofs of well-typedness, and you don’t need to inspect the proofs before forming the term, only later, when proving that your function is well-typed. I’m not sure how this relates to the higher coherences problem, though.
Matt, Bob Constable seems to have stopped giving lectures on Nuprl at OPLSS (or, at least, he didn’t when I was there last summer). He’s visiting MIT now, so maybe I can go visit him and ask him about it. I also can’t seem to find a download for Nuprl, only MetaPRL. Is using MetaPRL an ok substitute for Nuprl, and, if not, is there some way to get my hands on Nuprl? (I tend to understand things best by playing with them.)
Yup.
It doesn’t AFAIK. I shouldn’t have emphasized it.
My bad, you’re right. He did in 2010, ’11, and ’12. The videos can all be downloaded.
Not that I know of. You could try MetaPRL. Supposedly it includes the same “Computational Type Theory” as a logic, but the logical framework works differently than Nuprl’s. I haven’t tried either one actually, I just stared at the rules.
I have plenty of background in untyped programming, but I’ve never been able to wrap my head around the idea of using it for mathematics. It’s just so totally contrary to the way I think about mathematics, even before I learned about type theory. This reminds me of the frustrating time I had last year trying to understand in what sense the “meaning explanation” was supposed to explain anything.
It occurs to me now, however, that this is ironic because the dominant foundation for mathematics, namely pure set theory, is also unityped. Is that a fair analogy? In set theory, we have a bunch of things, and we have rules that allow us to collect these already-existing things into groups called “sets”. Whereas it sounds like you’re saying that in “untyped type theory” we also have a bunch of things, and we have rules that allow us to collect these already-existing things into groups called “types”. It seems to me like a step backwards in foundations of mathematics (or rather, the failure to take a step forwards from set theory), but maybe I can understand better at least what’s going on.
I was at OPLSS ’11, but I don’t remember learning about nuPRL. Maybe I’ll try to find my notes. I do vaguely recall now, though, starting out once trying to learn nuPRL and giving up in frustration because I couldn’t find an actual implementation of it that I could run.
I understand if untyped programming and math don’t seem to fit together. The way Nuprl combines them is very clever and unconventional. I wish they would advertise it more, and let anyone try it. Nuprl usually gets cited as an implementation of ETT, but I feel that that’s missing the point.
Yeah all sets have one type, since material set theory is a “single sorted” first order theory. But you technically need to account for the first order logic itself too. The rules about sets are axioms in the logic, not actual language rules. I’m sure you understand this, I’m just reminding you. The actual FOL language has a type of objects, a sort of propositions, where each proposition is a type, and the usual rules for proofs in a proposition. Then you have set theory as the standard library. This might seem like a nitpick, but FOL proofs really are more like typed programming in the usual sense than in the program spec sense. In Nuprl, even propositions and proofs work like untyped programming. Only judgements and derivations finally impose strict structure.
Whether or not untyped or mostly untyped theories are good for math is something I dare not state an opinion on. But for programming, you’re given some hardware to program, and some languages are more suited to the task than others. ITT has too much structure for programming machines with registers and memory words. That’s my opinion. I think C actually had it right regarding how to use types. For programming, fancier types than that are poor man’s program specifications. I’m not an expert in modern compilers though, so people may be getting more mileage out of fancy types than I realize. But not dependent types yet.
You’re telling me that in nuPRL, even after you prove something, you have to prove that you’ve proven it?
Personally, after reading about heartbleed, I’m even more surprised than I used to be that anyone is still programming in C. For many or most applications, I think correctness is more important than speed, and for that you want to abstract yourself away from registers and memory words as quickly as possible. (Of course, I’m a mathematician, not a programmer, but I think there are plenty of programmers who would agree.) However, that’s getting to be quite a digression from the subject here…
Depending on what proof you want, yes, in general. The explanation is a bit involved.
Ignoring extraction, Nuprl’s only judgement is an inhabitation judgement. If you’re thinking of a type as a proposition, you would usually just directly show that it’s inhabited at the derivation level. But if it’s a program type, you might write an untyped program, then derive the inhabitation of the proposition that your program is an element of the program type. But by propositions as types, you can actually do either one in any case. One nifty example of combining these points of view is that the Y combinator is actually a proof of “uniform” well-founded induction. That’s well-founded induction where the induction predicate is erased from the computational interpretation. (If I’m remembering right.) Of course, this is the sort of situation where you need an additional derivation to back up your claim that your proof really proves something. Nuprl’s elementhood/membership proposition
x in Tis actually a special case of extensional propositional equality:x = x in T. That Nuprl uses it to assign types to untyped programs is, in my opinion, it’s central cleverness. It’s not material set theory though: assuming elementhood is either forbidden or just useless, depending on whether the proposed element can already be shown to have that type.Not so fast. All I said was that I think C does structure-providing types the right way. (“structure-providing” for lack of a better term. “structural” is taken.) I did not mean to advocate coding straight C. My ideal system would have C as the unsoundly-typed language–rather than an untyped language–and put Nuprl-style types-as-specs on top. Security and correctness would come from the types-as-specs. In principle you don’t need abstraction for correctness and security. In practice, you would want higher level abstractions for human understandability and portability, but that’s not foundational. Low level programming will never completely go away, and C + specs does it right. (Well, you know, roughly. I’m not saying C’s design was perfect.)
Yes let’s not talk about the awful security situation of programming in the wild. There are too many issues, too many nasty interactions with other practical concerns, and too many opinions on what should be done about it. That conversation would take forever.
Interesting, thanks. I need to go away and think about that for a while. Has anyone tried to design a similar system that is intensional?
Umm. Hrm. I guess I’d need to know what you mean by “similar” and “intensional”.
By “intensional” I mean “admitting a homotopy interpretation”. Feel free to be as flexible as you like with “similar”.
ATS and Idris are intensional, I believe. They are somewhat similar to Nuprl in that they are intended for strongly typed programming. But last time I checked, ATS is not really geared to be nice for proofs. Idris seems a lot like Coq, but with imperative programming bolted on. It might be using UIP, I forget. Ynot is literally just Coq with imperative programming bolted on. I would guess these are not what you’re looking for, but I don’t really know what you’re looking for.
As far as things that don’t exist yet, a lot depends on whether an interpreter for dependent types is possible without strict equality, and whether there’s a good computational interpretation for HoTT. If there’s no good computational interpretation, then I can’t imagine anything where homotopy and reasoning about programs play nice, other than to go down to set theory. Otherwise:
If there’s some type theory with an interpreter for (parts of) itself that does without strict propositional equality, I’d say make sure the interpreter doesn’t need to look at proofs. Just add this as a primitive if you can’t construct it. Who cares about strong normalization anyway? This way you’d have a nice homotopy programming language. The ability to reason about, then reflect quoted stuff would be kind of like an intensional, syntactic version of how Nuprl reasons about programs. (But be aware that reasoning about syntax is a nuisance.)
Otherwise, you might as well take Nuprl itself, or something very similar, as the theory of strict equality and code up the computational interpretation of HoTT on top of it. The details here would go back to the stuff we were talking about with the right way to combine strict and weak equality.
Ok… more to go home and think about. (-:
I’m curious why you’re interested in Nuprl. I figured it’d seem quirky and unrelated to a mathematician. Please let me know when you have time.
It does seem quirky and unrelated. But I want to understand type theory, even the aspects of it that may not seem immediately to be related to homotopy. We’re at the stage of “exploring the design space” for homotopy type theories, and I think the more we know about what other parts of the design space for type theories in general have been explored, the more possible ways to design a homotopy type theory we’ll be able to think of.
OK, believe it or not, I’ve been working on the interpreter/semisimplicial type problem basically this whole time. I feel like I’m learning a lot. This message is kind of all over the place because I’m summarizing the possibly relevant ideas I’ve had in the past month.
I’m once again leaning towards thinking it’ll work. I was actually using the wrong handles for contexts. After I changed that, I was able to push through the weakening and substitution lemmas. But another hole remaining in the proof is causing another, somewhat similar problem, which is why I’m not done yet. More on that later.
I’m thinking a better name for handles (which was the new name for “Outrageous…” structures) is scaffolds. Like scaffolding in real life, these scaffolds are temporary structures to help construct what you really want. I’m going to try to use “scaffold” consistently from now on.
I did have a new idea towards why it might not work though: Something like the Reedy fibrant version of semisimplicial types is actually a bunch of big neutral terms. It’s stuck trying to apply the little x’s to the big X’s. For this kind of neutral term to be well typed, each one of those applications imposes a definitional equality constraint. An interpreter would be able to build this, which means it has to build up any number of definitional constraints at any dependency level.
Jason’s
repfunctions didn’t build neutral applications, and interpreters for stratified systems build up neutral terms only at a fixed set of dependency levels. But I haven’t thought this through. There could be an easy tweak torepto build applications. And the combination of neutral applications and dependency building as the limiting factor seems kind of far-fetched, since those are not problematic individually. But it provides a tighter characterization of the problem than my older negative ideas.I watched Peter Lumsdaine’s seminar video on semisimplicial types. It occurred to me that getting Reedy fibrant diagrams from inverse categories seems to be pretty much exactly what very dependent functions are supposed to do. Does that seem like a good homotopy interpretation? If you’re insanely lucky, insanely dependent types might be Reedy fibrant diagrams from Reedy categories. (But that’s a wild guess, since I don’t know what a Reedy category is!)
Also towards the end of that video, he said something like “Taking the limit of definitional equalities is known to be impossible.”. Do you know what result he’s citing, or is he just saying that you obviously can’t internally take the limit of something in the metatheory? Because the limit of Reedy fibrant diagrams seems kind of like a limit of definitional equalities, by the neutral application idea above.
Speaking of very dependent functions. The main thing that doesn’t work in my old proposal for constructing VDFs is when the well founded relation has “diamonds”. That’s the CS term for when a directed graph has distinct paths between the same two nodes. (I dunno, maybe you call it that too.) From an inverse category point of view, this diagram should commute. From a dependently typed module point view (the original use case for VDFs), this requirement is a sharing constraint. For example, an A depends on a B and a C, but requires that the B and C are sharing the same D. In my construction, there would generally be separate D’s for the B and C, which is wrong.
I came up with a simplified Reedy diagram thing as a use case for the interpreter I’m working on. I call it “chained types”, and it looks like:
So pretty much the simplest possible thing that has neutral applications at all dependency levels. I proved that the pattern stays well typed at all levels. The proof is straightforward but surprisingly long. It includes utility definitions that should also come in handy for semisimplicial types.
The main reason I’m writing is to ask a question about how I should try to do the interpreter. I’m going to have to tweak most of what I have to work around the problem I ran into, so I would like to discuss the options.
In order to interpret a term, you need to also interpret its type. This did not seem like any big deal to me because for a sensible type system, when you derive a term in a type, you can also derive that the type is well formed. That’s a totally standard metatheorem, and since for an interpreter, well formed types correspond to types we have an interpretation of, I figured there’d be no problem interpreting both at once. Maybe I should have seen it coming. Maybe I’m just a programmer, slow to pick up on semantic subtleties. But in the metatheorem that says inhabited types are well formed, some rules, like application, need to invert the derivation from the IH in order to build the result derivation. This works fine for syntax, but the corresponding obligation in my interpreter is to invert the interpretation relation. But if we do that, we need to show that the stuff we get actually has anything to do with what we’re using it for. Another coherence issue. Or at least a need for appropriate equations.
Since I solved the coherence issues for the structural lemmas by adding a new scaffold for semantic contexts, I figured if I added some kind of similar scaffold for interpreted types, I’d be set. An experiment seems to confirm this: If I prove injectivity of the constructors of interpreted types (which I can’t without adding a scaffold), then I can prove that the interpretations of terms are unique, which allows me to prove a specific enough inversion lemma.
“Outrageous…” actually had a scaffold for interpreted types: a universe construction. But Conor seemed to be using it to keep the codes small, not to solve coherence issues, so I took it out, because the inductive family version isn’t small anyway. The scaffold in my case might be a universe construction, or it might have to be something analogous for maps from contexts to types, I don’t know yet.
That’s one of my ideas for a solution. Another one is to try to avoid the problem in the first place by adding enough annotations to the terms so that the inhabited->well-formed metatheorem does not need inversion. For example, applications would be annotated with the result type of the function being applied. Hopefully then, there would not be a need for fancy inversion lemmas in the interpreter either.
A third idea is similar, but might perform better. Extra annotations add redundancy which gets interpreted redundantly. Instead of adding extra annotations to the terms, I would add it just outside the terms to explicitly say the terms’ types are well formed. If I can fit this extra stuff in the typing rules in a sensible way, and carry it through the interpreter, the hope is that I wouldn’t have to interpret types from term derivations at all. But I’ve given this option the least thought. Trying to preserve the connection between the separate term and type derivations through the interpreter might be just as hard as inversion.
More generally, there seems to be a spectrum of options in defining something tricky like semisimplicial types. How much of the coherence problem do you solve with raw syntax vs. with scaffolds? What I have now is somewhere in the middle, with semisimplicial types being defined syntactically, but where the interpreter still includes scaffold-based coherence proofs that probably could’ve been avoided with explicit substitutions.
Even just looking at an interpreter for a specific formulation of raw terms, this spectrum exists, because you can either handle coherence in the interpreter proper, or outside it by showing that the multiple expressions of a term caused by extra annotations all interpret the same way. The former is what I’ve been trying so far; the latter is more like the Autophagia interpreter.
The subset of type theory I’m trying to interpret for now doesn’t need a conversion rule, or anything similar. A more complete interpreter will have more choices based on how to handle that.
I would like to discuss what points on the spectrum seem most useful, elegant, simple, efficient, generalizable, etc. I was hoping to ultimately get a generic interpretation framework with pluggable type rules and models, but with this spectrum of options, it’s not clear anymore that the effort is worth it, from an engineering perspective.
By the way, have you had any interesting thoughts on Nuprl-like systems? I remembered that Nuprl can also be modeled with PERs on domain theoretic constructions, rather than PERs on terms. Domains supposedly have something to do with topology, and they can also be used to model uni-typed programming languages (like Nuprl’s underlying computations) by constructing a recursive variant (coproduct) type with cases for all of the things that would normally be separate types. I don’t know if that kind of construction ever comes up in topology, so it might not be a useful connection in this case, but it’s a thought.
I’m so excited that you’re continuing to work on this! Sorry that I took a while to respond; it’s final exam week here.
It does seem very similar. I don’t think insanely dependent types have anything to do with Reedy categories, though.
Those are what I was calling “towers” up above. I was able to get them (and also globular types) to work in my interpreter too. But they are indeed a good test case.
As for your main question, I don’t really understand it. Can you explain what you mean by “invert”, maybe with a simple example?
Yeah I noticed that chained types were equivalent to towers in the time since that post. So I was wrong when I said they don’t involve infinite dependency levels. The way you defined them above factors out the function types so they don’t have to be dependent anymore. This is a good idea, but it lead me to misinterpret it. I still don’t think the factored version would’ve counted as dependency building, though it doesn’t seem to matter now. And it doesn’t look like semisimplicial types can be factored.
But wait, you have a working interpreter? It’s for inductive-inductive syntax? Otherwise what’s wrong with it? Were the towers and globular types you interpreted factored, or more like semisimplicial types?
I didn’t post any of my code at first, partly because I was a little embarassed by it and didn’t have time to clean it up, and partly because I wanted other people to try their hand at it without being prejudiced by seeing what I’d done. But at this point, after all the discussion, perhaps it would be a good idea.
I tried a lot of different things, but the easiest to work with when aiming directly for things like towers, globular types, and semisimplicial types was a type theory with one universe and two sorts. You can see how far I got in that direction here.
The file mctt defines the type theory, inductive-inductively. There are a lot of constructors of judgmental equality because I just threw in new ones as I needed them. The file tower defines the syntax for towers, recursively, and similarly the file globular does globular types. The idea for both is to define an operation on contexts which when iterated, starting at the empty context, defines the context for n-fold towers or n-globular types. It’s harder to do the analogous thing for semisimplicial types; I think I know how to do it in principle, but actually writing it down is where the coherence problems come in when working with the inductive-inductive syntax.
The file extract is the “interpreter” which turns syntax into semantics. It first interprets contexts as left-associated sigmas, which seemed to be easier, and when applied to towers and globular types gives a “factored” version. But then it modifies this interpretation slightly to give right-associated sigmas, using the auxiliary stuff in the file context; and that yields the “unfactored” versions of towers and globular types.
I haven’t thought carefully about what-all kinds of Agda-special magic this uses, except that I tried to avoid induction-recursion.
Oh, wait: associativity of sigmas is a different issue from “factoring”. Both associativities are unfactored. Right?
Great! Unfinished code can be ugly; don’t worry about it. I’ve been curious to see where you actually got stuck. I haven’t looked yet, but you make it sound like it is interpreting inductive-inductive syntax. At this point, my suspicion is that coherence for II syntax is not fundamentally harder than all the equations that can potentially come up for raw syntax, just more painful because of dependent types. In fact, I’ll be impressed if your towers and globular types are unfactored, because those already seem to require heavy use of equations.
Yeah, dependent contexts always seem to be left-nested sigmas. Towers are more like right-nested sigmas. As for what I mean by factoring, starting with the recursive version of towers I wrote down way up there,
tower' 1issig A:Type,A->unit, which is equivalent toType. So thentower' 3would be equivalent tosig X0:Type,X0->sig X1:Type,X1->Type. If we use pi instead of arrow, that’ssig X0:Type,forall (x0:X0),sig X1:Type,forall (x1:X1),Type. A function of pairs is a pair of functions. This has a dependent version which involves substitution:forall a:A,sig b:B,Cis equivalent tosig b:(forall a:A,B),forall a:A,C[b a/b]. If we use this on that last version oftower' 3, we get:From this, (or maybe one more level) I jumped to the conclusion that distributing all arrows over all sigmas in the
tower'version would reproduce my chained type version. Come to think of it, maybe doing this distribution yourself is how you avoided equations in the inductive-inductive version of unfactored towers.But yeah, soon I will look at what you actually did.
OK, I’m looking at
mctt. It looks like you’re using essentially the same subset of type theory as me, but you organized it differently. Mine also has only right-nested pi and U for types, and application for terms. Your application is a kind of “delambda” operator which gets you an open term, which I presume you then substitute with_≪_. Is that your idea? Chapman’s? Or is it from the explicit substitution calculus?Huh, your contexts in
contextreally are right-nested. I figured you meant the types you interpreted would be right-nested sigmas, not the context they’re in. Or maybe that is what you mean, and you shouldn’t have called them contexts. Are they on the left or right of the turnstile?The “delambda” is from Chapman.
The contexts in context are an interpretation of things on the left of the turnstile. The first interpretation (ecxt) yields left-nested sigmas, but then I used that to define a second interpretation (ecxt') giving the right-nested Contexts, and a third (extract) which gives right-nested sigmas. Note that the towers and globular that I fed into the interpreter are also on the left of the turnstile; I did this futzing around with left vs. right nesting because I wanted the end results to be right-nested.
I’m playing with a Coq port of
context.Here’s how it starts:
But is that really a context? How many elements in this “context”?
Check fam bool (fun b=>if b then emp else fam nat (fun n=>emp)). fam bool (fun b : bool => if b then emp else fam nat (fun _ : nat => emp)) : ContextAnd what de Bruijn index do I use to get a
natout?I’m basically making the same point as Conor (when he defined contexts to be left-nested for this reason in “Outrageous…”) but snarkier. I’m not saying what you did is wrong, just that it’s probably weird to think of it as a context. I hope I’m not being too mean. I appreciate getting to read this. Anyway, I’m probably obsessing over the wrong part.
Yeah, you are totally obsessing over the wrong part. (-: Left vs right nesting is just a triviality of presentation; I only defined the Contexts in order to make the output “look nice” the way we’d hope a definition of towers, globular types, or semisimplicial types to look, rather than an alternatively nested but equivalent version.
I’m also amused that a few comments ago you said “Unfinished code can be ugly; don’t worry about it” but now you’re taking me to task not over any contentful aspect of the unfinished code, but over the naming of a trivial part of it. (-: I called them “contexts” because they’re the semantic object that syntactic contexts get interpreted as. It’s true that they don’t behave like syntactic contexts, so that concepts like “number of elements” don’t apply to them. But they are, for instance, the objects of a “contextual category” that we are interpreting the syntax into.
But, again, this is totally the wrong part to obsess over. If you have any suggestions for a better name for these things, I’d be happy to listen.
Well I didn’t say it was wrong. I agree that the result should be right-nested, I’m just surprised about how you did it. You shouldn’t worry about problems that you didn’t get to address, but the name of something finished is something deliberate, and to most programmers, good naming is not a triviality. But I didn’t mean to take you to task, just to raise what I thought was a legitimate issue. I don’t know contextual categories, so maybe I was just being narrow-minded about what a semantic context is. If right-nested contexts are a well-understood alternative that do what you want, then I’m no longer concerned.
I think good naming is just as important to mathematicians, and if I had ever finished it, I would have put more thought into it. But I don’t think that code will ever be finished now, because I don’t know how to solve the coherence problem with inductive-inductive syntax.
I am curious, though, if you have another way in mind that you would use to make the result right-nested?
(BTW, I misspoke: I didn’t mean contextual category, I meant category with families. It’s so hard to keep straight all the slightly different categorical models of type theory.)
I think of a right-nested sigma as a type. My type system only has pi, so I added an extra layer of “signatures” for right-nested sigmas. But they are still on the right, and interpret to regular sigmas. If you have the pieces (except the last one) in a left-nested contest, you can zip them over to the right to make a signature one step at a time. It’s basically the sigma formation rule.
There do seem to be a lot of approaches to modeling type theory with categories. I don’t know any of them.
Okay, so you basically have sigma-types in your type theory and you sigma up the context before interpreting it. I guess that makes sense. There’s something weird about that to me, but I can’t put my finger on it. (-:
Or I sigma it up afterwards. (And then I can take sigmas out.) I haven’t decided which yet. But in either case, I wouldn’t think of the right-nested sigmas as a context.
Your interpreter is clean. (Well, I still don’t know about the right-nested context business; seems weird.) I hope I can find a raw syntax interpreter half as clean. Maybe the extra annotations idea will do that. But in the mean time, I put up the code for the messy one I’m in the middle of.
The latest working version of substitution is off to the side in
Old/InductiveScaffolds/. The newContext.vcompiles, but the aspects of substitution done inSimpItrp.vhave not yet been updated to use it (as ofr2).Let me know if you have questions, comments, or criticisms. (I think I deserve some payback for fussing about
context. 🙂 Hint: The ugliest stuff is toward the end ofSemiSimplicial.v.)Inversion is just the general trick that if you have an inductive family with another inductive type as an index, you can define a version of (non-recursive) elimination for the family where some or all cases are left out because of a constructor mismatch in the index.
The simplest useful example is probably the proof that
~(S n <= O), in the Coq standard library. The wayleis defined, by inversion onS n <= O, both thele_nandle_Scases would require thatObe a successor, so you can prove anything without getting subgoals.Coq’s
inversiontactic tries to do inversion this automatically, and it usually works, technically. Proving inversion principles from scratch uses some of the same tricks as encode-decode proofs: large elimination and partial inverses of the index constructors. The large elimination lets you observe that inductive objects from distinct constructors are unequal. The partial inverses let you prove that the constructors are injective. Coq also hasdiscriminateandinjectiontactics to do just those parts. There’s also apparently acongruencetactic which tries to be the cleverest of all.But come to think of it, the real problem I ran into is not eliminating bad cases, but something else that’s inversion like in that we want to get out information from an inductive family as long as it agrees with what we already know. Essentially, I had a proof that
"forall a:A,B"interprets toXand a proof that"A"interprets toA', and I wanted to know that this meant thatXmust beforall a:A',B'for some interpretationB'of"B". (Actually I just wanted to knowB'.) But all I could show was thatXmust beforall a:A'',B', whereA''is some possibly unconnected interpretation of"A". That’s not good enough because thenB'was interpreted in the wrong context.So like I said, if I add more structure on top of interpreted types, I think I can prove a uniqueness lemma that provides a path between
A'andA''since they’re interpreted from the same syntax in the same context. I’ve already decided to try this to see if it works, but the more I think about it, the more I suspect that Autophagia-style interpreters are much easier, and Outrageous-style interpreters are not worth the trouble.What I was trying to explain the other day is that I believe I only have to deal with this problem because the “inhabited types are well formed” metatheorem uses an inversion on the well formedness of
"forall a:A,B"in the application case. That inversion just concludes that"A"is well formed, and"B"is well formed once you add"A"to the context.Actually, come to think of it, outside of my subset type system, I don’t think inversion would actually let you conclude that, because of inductions in type expressions. Whew, I sure lucked out to try a subset first!
What am I saying? An induction in a type expression would appear as such, not as
"forall a:A,B". I got confused because the type of an induction in a term can be anything, which tends to foil inversion in other cases. I talk too much.But still, it’s good that I’m learning all this stuff the hard way for a simple subset.
Okay, I think I understand the question you’re asking now. I think my inclination would be to put as much of the scaffolding into the interpreter as possible and keep the syntax simple. That way the user of this system (e.g. someone who wants to use it to define semisimplicial types, or some other new higher structure) has the easiest job possible, and doesn’t have to see the extra scaffolding inside the interpreter because it gets forgotten about after you run the interpreter and get out the actual types you want. Or am I misunderstanding?
I guess there’s a possibility that adding extra annotations to the syntax might actually make it easier for the user to construct the requisite syntax for whatever higher structure they want to study, since they also need to prove that their syntax is well-typed in order to feed it to the interpreted. But I don’t know whether to expect that or not.
No no, the user would provide the same thing in either case. The choice is whether we turn that into semantics directly, or add a bunch of extra annotations first. The latter would just be a syntactic metatheorem of some sort. I’m hoping that the latter would get rid of coherence issues completely, because we’re essentially saying we only care about this particular way of deriving the term, and everything else you need to know about it to interpret it.
Specifically, the extra annotations would have to include explicit substitutions, explicit conversions, and type annotations on elimination forms (and probably also the explicit substitutions and/or conversions). I’m not positive a sufficiently explicit form exists, but I suspect it does, since I’m imitating the explicitness of inductive-inductive syntax, and its ease of interpretation.
Before I said all this extra stuff would lead to redundancy and slow things down, but I’m starting to think that the alternative–computing with structured semantic contexts and types inside the interpreter–would be about as bad. Really I have no clue; I just know they’d both be way slower than an interpreter should be.
In other words, this is a difference in how the interpreter is implemented, not what it does. I should have said that clearly before. The only difference a user might possibly see is whether it’s very slow or extremely slow.
Okay… then I’m not sure I have any opinions. Whatever works best, I guess.
I think what he meant is that the syntactic category of a type theory doesn’t have, say, equalizers.
However, unless I misunderstood what he said at that point, I think it’s not right — the problem with general Reedy categories is not that the limits are too complicated, it’s that there are also *colimits* that get into the picture.
Hmm. Well rather than try to fully understand what that has to do with defining simplicial types, I’ll continue to try to make a useful interpreter, starting with trying to finish the one I started. Someone else can decide what the best definition is, once we have interpreters to play with. With a complete enough interpreter, it seems you could even interpret all the higher coherences of the functor definition, assuming they’re recursively enumerable, and all fit in a fixed universe.
Are you looking for something like this? The nesting is a bit wonky because I haven’t put much thought into it, but, given n, it does build a term involving k-ary applications for all the k’s 0 up through n.
Fixpoint rep3 (n : nat) : forall T, rep_arrow T n -> Type := match n as n return forall T, rep_arrow T n -> Type with | 0 => fun T f => f | S n' => let rep' := @rep3 n' in fun T f => forall (x : T), rep' T (f x) end. Eval simpl in forall f, rep3 3 Type f. (* forall (f : Type -> Type -> Type -> Type) (x x0 x1 : Type), f x x0 x1 : Type *) Fixpoint rep4 (n : nat) : Type -> Type := match n with | 0 => fun T => forall f, rep3 0 T f | S n' => fun T => forall f, rep3 (S n') (rep4 n' T) f end. Eval simpl in rep4 2 Set. (* = forall (f : (forall (f : (forall f : Type, f) -> Type) (x : forall f0 : Type, f0), f x) -> (forall (f : (forall f : Type, f) -> Type) (x : forall f0 : Type, f0), f x) -> Type) (x : forall (f0 : (forall f0 : Type, f0) -> Type) (x : forall f1 : Type, f1), f0 x) (x0 : forall (f0 : (forall f0 : Type, f0) -> Type) (x0 : forall f1 : Type, f1), f0 x0), f x x0 : Type *)Aww you shouldn’t have… Because I’m not currently looking for counter examples.
But let’s see… OK,
rep_arrowis missing. It seems like it should be:I need to think about what rep4 is doing.
Yes, that’s
rep_arrow. Sorry for the copy/paste fail.Here is a simpler version of rep4 that is easier to understand (but does something different; it only gives a single n-ary application):
Fixpoint rep5 (n : nat) : Type -> Type := match n with | 0 => fun T => forall f, rep3 0 T f | S n' => fun T => forall f, rep3 (S n') T f end. Eval simpl in rep5 3 Set. (* forall (f : Set -> Set -> Set -> Type) (x x0 x1 : Set), f x x0 x1 *)My
rep4simply says, “well, to get all the k-ary applications, let’s just throw them in the types arbitrarily”.Well
rep5isn’t doing much of anything. I guessrep4is an example of what I was saying. You did it again… But like I said, I didn’t seriously doubt it could be done.I won’t have any hypotheses about things that can’t be done for a while now, since I have multiple ideas to try before I get stuck. And next time I say something can’t be done, I’m going to be more precise about what I’m saying can’t be done.
I think this whole time I had misinterpreted the problem you ran into.
I thought the higher coherences you needed were propositional equalities in the metalanguage, but now I think you meant definitional equalities in the object language. I got confused because:
1. As far as I knew, inductive-inductive definitions would somehow come out not being provably set-level.
2. Since I hadn’t given explicit coercions much thought until today, I hadn’t realized definitional equality coherences even made sense.
So what happened was that I started considering the “extra annotations” approach, and I figured it’d be purer to include explicit substitutions. This means I defined a new set of raw terms and typing rules, just that the terms had explicit substitutions and coercions. I defined a translation on raw terms from the old system to this one, and tried to prove that it preserved typing. It didn’t work, which I was half expecting, since I hadn’t actually used any coercions yet. So I switched to paper to experiment with what coercions I needed, and then I realized, for the first time, the infinite regress of needing coercions to push substitution through substitution’s coercions.
So I had kind of assumed that the languages defined with induction-induction were actually proper dependently-typed languages, but now I’m not sure. They all seem to use explicit coercions (if not also substitutions), which already might cause coherence problems with coercions to move coercions in the type. It’s not induction-induction per se that’s the problem; it’s that it forces you to use the wrong language! Some funny class of language with even more structure than ITT, and not enough coherence. At least AFAICT. Does anyone know of any result that proves an explicit coercions calculus complete w.r.t. a regular dependent type system? (Explicit substitutions alone seem OK.)
I think I understand better now why Jason proposed inductive definitions with constructors for strict equality. These are basically quotiented inductive definitions, right? That does seem to be the usual way to think of definitional equality.
That’s true… except that I also considered the option of a higher inductive-inductive definition of syntax, in which case the judgmental equality of the object language would be the propositional equality of the metalanguage. I tried to explain what the coherence issue would look like in both cases, but I guess I failed to make this clear; sorry!
I think it depends on how you define the language. As I said in the post, I think you can eliminate the coherence problems by adding a constructor of judgmental equality asserting that any two coercions of the same term along parallel judgmental equalities are equal. Possibly Chapman does something equivalent by using a heterogeneous notion of judgmental equality. But if you do this, then the interpreter is no longer definable in the obvious way (at least, not without UIP).
Yeah, I think I understand the HIIT proposal now too, but that’s not what I was talking about. Yes, I think you should’ve started by being explicit about the problem in the case of a standard interpretation. That would’ve helped me.
Good point about how you could truncate the definitional equalities to get back coherence, but yeah, that’s a problem for the interpreter without UIP. Now I understand what you were saying there too!
I think you’re right that we could do the interpreter in more ways once we have infinite-dimensional diagrams to express commuting diagram coherence. But for getting to that point, it seems that we want a strictifying interpreter, and that explicit coercions are a dead end.
I was writing with a homotopy type theorist audience in mind, who I assumed would think the HIIT version seemed more natural. (-: But I’m glad we’ve got it sorted out now.
Hi guys. The good news is that it looks like my interpreter can be made to work for set-level semantics. The bad news is that that’s it. I do have one more idea, but it would be a major change, and I don’t actually have any reason to believe that it would work either.
It still seems that I need to prove that the interpretation relation has unique outputs before I can prove that it’s total. Otherwise, the bits of interpreted stuff from the IH don’t necessarily fit together. But I’m stuck on a coherence problem in the function application case of the uniqueness proof. Both the function and the argument have a type dependency on the function domain. So I think I need to somehow have a coherence handy for two paths that show the domain is unique in order to use the uniqueness of both the function and argument while keeping the result well-typed. But how do I engineer for such a coherence to be available, without infinite regress? Maybe there’s some trick, and I don’t need this coherence? Any ideas?
Wellp, I guess I finally got to see why this is fundamentally a coherence problem, and why it seems hard to you category theorists. (Took me long enough.)
So how do these strictification theorems work anyway? Perhaps you need strict equality over arbitrary types in order to bootstrap an infinite-dimensional strictification. Just a thought, I have no intuition about that, other than that doing without strict equality seems hard. It seems like part of the reason why an interpreter would be helpful is that it actually seems to provide a notion of strict equality, at least for the results of interpretation.
Would that be easier or harder than this? It actually looks like it might be the same, right?
I suspect trying to design a type theory that acceptably combines strict equality and the homotopy interpretation could provide hints for what’s missing from the current picture that makes things seem so hard. The reason is that there seems to be a certain “computational weakness” to the equality type in ITT: For set-level stuff, it seems like it can be simulated with hand-rolled per-type equalities, along the lines of setoids. And on abstract types (the problem, since otherwise everything would be set-level), we can’t hand-roll an equality, and the built in one has coherence issues, unless we assume things about the equality on that type. So perhaps ITT equality doesn’t actually extend what we can do in situations that don’t already involve equality. (I can make this more precise, if someone wants to look for counterexamples. But this might have already been proven one way or the other.) If so, then maybe we have a “no coherence dimension building” problem. All the examples of infinite dependency depth so far are very self-similar, and evidently don’t need infinitely many forms of coherence.
Perhaps the parametricity of ITT makes it impossible to express full coherence in the abstract. In other words, there’s some combination of models such that there’s no way to generally express full coherence in a way that’s uniform/parametric/continuous/natural. But I don’t know why that wouldn’t also affect finite dimensional coherence. Maybe a conflict between well-founded and non-well-founded infinity? Some funky model where the next dimension is actually in a higher universe, so you have size issues? Just grasping at straws. Does parametricity have anything to do with “model invariance”? In other words, can there be a model invariant statement of full coherence?
BTW, I’m kind of getting interested in this stuff, so if I’m not making sense anywhere, please set me straight. 🙂
I’m planning to try to finish my set-level raw syntax interpreter. It could be handy for you guys too, say, to interpret into a model category. As a reminder, the repository is online. Let me know if you have questions, ideas, or suggestions. (But remember, it’s not done yet.)
Do you know this for a fact? That semisimplicial types need coherences at all dimensions? You do don’t you? 🙂 This has something to do with why those funny type families are allowed to be called semisimplicial types, right? If so, can you point me to relevant theory or result? I have an idea for proving that you can’t internally enumerate the truncations, based on the “no coherence building” intuition.
I didn’t say that semisimplicial types need coherences at all dimensions. I don’t know that; I only know that I haven’t been able to define them without seeming to need an infinite regress of coherences.
It ought to be possible to make precise some statement along these lines, though. For instance, one could prove that the nerve of the semisimplex category is not equivalent in the Joyal model structure to any finite-dimensional simplicial set. Maybe someone’s even done it. But that sort of result wouldn’t necessarily imply nondefinability in type theory; I would expect it to be harder to prove that an “infinite-dimensional coherence structure” is not internally definable.
I guess it’ll help if I tell you what I have in mind.
Capturing all the definitional coherences in an inductive-inductive definition of intrinsically-well-typed terms seems to hard. So does capturing them all in an inductive family interpretation relation. (I haven’t tried it, but it seems like it’d be harder than semisimplicial types in the first place.) But it shouldn’t be a problem for raw terms and typing relations.
So I could define a version of ITT + inductive families that uses explicit coercions, and enough other deliberately-annoying stuff to ensure that some sequences of neutral terms using abstract types involve definitional coherences at all dimensions. What I was trying to find out by asking you is whether semisimplicial types really would provably be such a “pathological” case.
If we can find a pathological case, and if the language is complete wrt usual ITT + inductive families (that is, we can metatheoretically add the coherences in a type-preserving way), and if–as I’d naively suspect–coherences don’t appear out of nowhere due to reduction, then I think this would formally prove the “no coherence dimension building” restriction of ITT + inductive families. This would imply that the pathological case cannot be internalized as a function.
“No coherence building” is a refinement of my earlier “no dependency building” and “no neutral term building” ideas, which weren’t right. Loosely speaking, we would be showing that without additional structure, ITT + inductive families can be interpreted as involving implicit, externally-indexed definitional coherences, which makes internal full coherence inexpressible, like an omega universe is. This plan is based partially on your idea that definitional equality could be interpreted as fully coherent paths. It’s also based on my observation that having to interpret application with arbitrary abstract types screws everything up.
I can’t ask you to actually find a pathological case for me since I don’t have a concrete language with explicit coercions yet. And I’m not even sure I want to pursue this. But I figured semisimplicials ostensibly being pathological had something to do with the reason why the semisimplicial types we’ve been talking about correspond metatheoretically to some other notion of semisimplicial types, which that seminar video led my to believe. So I wanted to find out what you could tell me.
Your second paragraph is encouraging. I don’t know what a nerve or Joyal model structure is, but if the semisimplex category is provably infinite dimensional in any intuitively-related sense, then it’s could be close to what I was looking for. But we’re gonna have to figure out what distinguishes semisimplicial types from towers or globs, if this is to work. You were able to define unfactored towers and globs without interpreting definitional coherences, so that seems to be the key. As I hope the above paragraphs made clear, I was planning to come up with some funny proof-theoretic reason why objects needing unlimited coherence dimensions don’t exist. I was just checking to see if you knew that semisimplicial types needed that.
Sorry, I’m having trouble with your language. What is a ‘definitional coherence’? What would it mean for them to ‘appear due to reduction’?
Unfortunately, while towers are not infinite-dimensional in the sense I was proposing, I suspect that globular types are. So that may not be the right way to go.
One of the explicit coercion rules needed to move a lower explicit coercion in the type. If I understood correctly, this is the kind of thing you seemed to need infinitely many of to get an inductive-inductive representation of semisimplicial types.
How can this be? In the factored versions, globular types are a special case of towers:
Fixpoint tower n : Type := match n with O => unit | S n => sigT (fun A=>A->tower n) end. Fixpoint glob n : Type := match n with O => unit | S n => sigT (fun A=>A->A->glob n) end. Fixpoint glob2tower n : glob n->tower n := match n with O => fun x=>x | S n => fun gl=> let A := projT1 gl in let f := projT2 gl in existT (fun A=>A->tower n) (A * A)%type (fun p=>glob2tower n (f (fst p) (snd p))) end.I would’ve thought they were both 0-dimensional in some sense.
Well, you’ve defined a functor from globular types to towers. I don’t think that justifies calling the former a “special case” of the latter, since the functor isn’t full. But regardless of one’s opinion on that, it certainly doesn’t imply that the diagram shape for globular types can’t be higher-dimensional than that for towers. Your functor isn’t induced by a map of diagram shapes, but even if it were, there can be maps from lower-dimensional things to higher-dimensional ones and vice versa.
I conclude we’re still not understanding each other then, because you’ve already defined both of them without trouble, but semisimplicial types are still giving us trouble, and I’m talking about a possible reason why.
I guess
glob2towerdoesn’t formally accomplish anything, but the point is that globs just have two arguments where towers have one, so you don’t need any new tricks to interpret the definition of globs.By special case, I just meant a globular type is a tower where the types are all products of some type with itself. But that might be a stupid way of thinking for what we’re trying to do. You need to cut me some slack since I don’t know homotopy theory.
What I’m saying now is that the particular reason I proposed before — that perhaps the semisimplex category is “infinite-dimensional” in a particular precise sense — probably isn’t right, because the globe category is probably infinite-dimensional in the same sense. Does that make it clearer? Of course, that doesn’t rule out there being some other precise sense in which the semisimplex category is “infinite-dimensional” but the globe category isn’t.
OK, I see what you meant, I think. So in conclusion, we still don’t know a way to prove that semisimplicial types are infinite in the sense I would need?
(And keep in mind I still don’t know if I’ll be able to come up with a no coherence building result anyway, so there might not be any precise sense we’re talking about after all.)
Yes, I think that’s right. But even with these two gaping holes, now that I mostly understand it I think this is the most promising idea I’ve heard yet for actually proving the undefinability of semisimplicial types in ITT. So let’s not give up. (-:
Okay, I think I’m slowly getting a picture of what you’re proposing. Can you explain in more detail why this would imply that the pathological case couldn’t be internalized?
Analogous to the “no dependency building” idea before, if we had an internal pathological case, then it must have some maximum coherence level it uses (because that’s true of all terms). But by assumption, there’s some natural number we could apply it to so that it’d reduce to a term using a higher coherence than that, which contradicts no coherence building. Is that what I was supposed to fill in?
Okay, I think I see. Let me recap to make sure I’ve got it. You’re proposing to define a version of ITT in which coercions are all explicit, which includes definitional coherences at all levels, and a translation from ordinary ITT into this explicit one. Since the translation acting on a finite term will produce a finite term, the result can only involve finitely many definitional coherences, and thus in particular only coherences with some finite upper bound on their dimension. So if we could prove that semisimplicial types can’t be expressed in the explicit version without definitional coherences of all dimensions, then they couldn’t be in the image of the translation from ordinary ITT. Is that right?
Yes, essentially! But you left out the issue of reduction. We don’t need the hypothesized construction of semisimplicial types to immediately involve infinite coherences. Suppose the hypothetical construction is called
simp. We’d be hypothesizing thatsimp 0reduces toType,simp 1reduces to{X0 : Type & X0->X0->Type}, etc. We need to show that for all m, there is an n such that the normal form we demand ofsimp ncannot be expressed without definitional coherences of level m. This means that there’s some n wheresimp nreduces to involve higher level coherences than it started with, which was some finite k. (As canonical terms, numerals wouldn’t need coherences.) But in this plan I would be expecting to show that coherences of a new higher level are never introduced by reduction. That’s the “no coherence building” part.I guess I finally got to see why this is fundamentally a coherence problem, and why it seems hard to you category theorists.
That’s actually kind of exciting to me. It means that on the one hand, my intuition that this is a coherence problem may have something to it, and that on the other hand, we managed to communicate a very vague idea across a fairly wide gap of disciplines. I find it promising for the future of the subject.
I’m sorry that I haven’t been able to have much of a look at your code yet. A flimsy excuse is that you’re using the Coq standard library, so I have to go to the extra trouble of installing a vanilla Coq in addition to HoTT-Coq. Also, it still takes me a lot of effort to read someone else’s code (and I suppose I could complain a little about your code if you like, such as a lot of lemmas with similar and abbreviated names and no explanatory comments). Any guidance on where to start?
So how do these strictification theorems work anyway?
In a fairly disappointing and unhelpful way. You prove (or define) that any (∞,1)-topos is obtained from a presheaf (∞,1)-category by a left exact localization. Then given an (∞,1)-category of presheaves on a small (∞,1)-category C, you present C by a small simplicially enriched category and show that the model category of simplicial presheaves on C presents the (∞,1)-category of presheaves on C. Then you do left Bousfield localization on that model category to match the left exact localization of your (∞,1)-category.
Would [modeling type theory in an (∞,1)-category without presenting the latter by a model category] be easier or harder than this? It actually looks like it might be the same, right?
Well, if we had a working interpreter that could interpret into things more general than the universe, we could use it to model type theory in (∞,1)-categories, by representing the latter internally to the simplicial model of type theory and then using the internal interpreter. But I suspect that interpreting into the targets that this would require may be even harder than interpreting into the ordinary universe.
For set-level stuff, it seems like it can be simulated with hand-rolled per-type equalities, along the lines of setoids.
That’s not entirely restricted to sets, is it? We can give type-directed definitions of “what equality should be” even for the universe (it’s univalence) and for things like products, sums, functions, and W-types without truncation restriction. It’s only (as far as I know) when we get into HITs like spheres that there’s no (known) way to “define” the equality types.
So perhaps ITT equality doesn’t actually extend what we can do in situations that don’t already involve equality.
Can you explain further? I don’t even know what you mean by “extend” — extend relative to what?
Does parametricity have anything to do with “model invariance”?
That’s an interesting question! But I don’t think I have anything more intelligent to say about it.
In other words, can there be a model invariant statement of full coherence?
Do you mean an internal statement? Finding an internal statement of “full coherence” (in ITT, not HTS) seems to be the whole problem that we’re up against here. But you seem to be saying that this is the same question as the previous one; why is that?
Well actually, now that I think about it, there are actually three coherence problems, or two, depending on how you count. Here’s one.
But that still doesn’t seem very convincing. Why should it have to be a surjection? We only want an interpreter, it doesn’t have to hit everything. So I dove in figuring the subset of the universe that would be involved wouldn’t be any worse than I chose it to be. And I still think that would be true if only we had strict equality. Without it, I forget that everything I look at is in the strict image of the function I’m defining, so things are as bad as the universe in general. So problem two of three is that there doesn’t seem to be any substitute for strict equality in this case, so we have to deal with the general universe’s coherence.
Problem three is the apparent inability to load up an inductive-inductive or inductive-recursive definition with enough coherences, which my approach works around but to no avail.
Well, coherence is easy. CS deals with coherence, though it isn’t usually higher-dimensional. Like how coercion subtyping should be coherent so that the coercions can be implicit without affecting the semantics. That’s actually a puny special case of full coherence for higher categories, I think, used in order to pretend a category is a poset. Anyway, I wouldn’t have thought type theory to category theory was such a wide gap.
That’s a fine excuse! I would have thought twice about using the standard library if I had known HoTT-Coq tossed it. I’m not using much of it, so I will fix that sooner or later.
My most severe abbreviations are the acronym prefixes I use. They’re usually just initials of the associated type, or something like that. Let me know if there are any that are particularly hard to remember. Basically I use prefixes to avoid possible future name clashes. Coq does not have bidirectional type checking or ad-hoc overloading, so names are module scope, and qualified names are a pain. Many type theorists love to bash languages like C++, Java, and C#, but this is actually one issue they handle better.
Utils.v is random stuff. Read it as necessary. A lot of it is not actually used by the latest code.
SimpSyntax.v is the language the user sees. Concentrate on
simpFamandSimp*OK. The lemmas there are mostly used by Chained.v, which is out of date.TreeSyntax.v is a modified intermediate version of the language that gets interpreted. Focus on
treeFam,TreeFamGood,SimpParamGood,tfGoodMap, andSimpParamGood_rect. The lemmas are to show that translation from SimpSyntax preserves typing. Out of lazyness,SimpParamGoodis still developed as a nested inductive family, although it doesn’t currently nest anything. (It used to nestTreeFamGood.) Adam Chlipala has a great bestiary of inductive definitions, which explains nested inductives.Context.v is structured semantic contexts, and a bunch of less-unimportant things to do with them. In particular, it handles some of the variable-specific aspects of substitution. The raw syntax uses computed substitutions, so the interpretation relations need computed substitutions as well. Unfortunately, the meat of the substitution code is in TreeItrp.v, but hasn’t yet been updated for the latest interpretation relations.
TreeItrp.v is where the interpreter (of TreeSyntax) is supposed to go, but most of the proofy stuff is left over from various old versions, since I tweak it as I need in order to try things. If you want to take a serious look at this soon, let me know, so I can turn it back into an almost proof with one nasty hole. And let me know if I should do this before or after I get rid of standard lib stuff. (The latter will take a little longer.) For now, just read up to
TreeCtxItrp, and maybe the statements of some lemmas, although the proofs don’t run. The final results of this file would be*ItrpTotal.Chained.v defines raw syntax for unfactored towers, and proves it type correct. But it uses an old version of SimpSyntax.v, so it’s not quite right. The new version will actually be a little shorter, since the change was to relax a premise in one of the rules. (It wasn’t wrong, it was convenient! ;)).
SimpItrp.v is old, why isn’t it in Old/? SemiSimplicial.v is a mess, but it starts out on the right track. Nothing surprising though. Old/ contains the corpses of many old attempts, and some other stuff I figured “Why not keep it?”. I don’t think you’ll get anything out of reading these.
I forgot to say:
*Itrpare the interpretation relations. They are defined recursively so that I don’t need inversion lemmas.AtCtxfrom Context.v is basically an interpretation relation for de Bruijn indexes.Well I’m sleepy now, but that might not be the problem; lots of terms there I don’t know. I’ll take your word for it that it’s unhelpful.
Yes, that’s what I was thinking. Before I ran into the latest problem, I thought the standard interpreter would give us the coherence definitions we needed to do more general interpretations, but I now doubt the current form of ITT-based HoTT can do any of that.
The problem with a hand-made equality for the universe isn’t the universe itself, it’s that we’d then need a hand-made equality for the arbitrary types of the universe. Clearly we don’t know how to make that. We could demand some suitable family to use as equality, to be bundled with the types, but then that’s not the usual universe anymore. But yes, that approach ought to work as long as it doesn’t require the analogue of infinite coherence dimensions. So, for example, we could try set-level model categories, or 2-categories, as models. I don’t know about HITs. It seems like a hand-rolled equality for a HIT should be a HIF (higher inductive family), but I haven’t given it any thought.
So I’m basically thinking that adding Id is a conservative extension, except stronger, because I believe that not only do ITT + Id proofs of ITT statements correspond to ITT proofs, but also that ITT + Id functions on ITT types correspond to ITT functions. This correspondence provides a (possibly) different function, but the two functions are “shallow equivalent”, by which I mean that they map definitionally equal inputs to definitionally equal outputs. (This is weaker than intensional equality but stronger than extensional equality.) There are wrinkles: we demand that the original function never outputs objects involving Id, and we provide no guarantee when the new function is given an object involving Id. Anyway I had something like that in mind. It’s a nice conjecture, but I don’t think we actually need to know if it’s true or not. It just guided my intuition. If it weren’t true, then Id could bring a significant amount of extra expressiveness, even to the problem of semisimplicial types, which doesn’t involve Id. But by the “use setoids” reasoning, and my application coherence problem, it seems that it doesn’t.
Well actually I don’t know the technical details of either, but my informal understanding of model invariance is that you’re demanding that everything means analogous things in various models, where the analogy is that the homotopical content presented is the same. My informal understanding of parametricity is that interpretations of the same thing into different models have to be related in some appropriate sense, and that, in particular, with an abstract type you get to plug in just about any relation you want. So they just seem rather similar, just by both demanding a certain correspondence between models. If I did more semantics, I’d be full of bad ideas about what the connections might be. But they both seem to be strong constraints on the language, so I was thinking about whether it might be a way to show that semisimplicial types are not expressible. But “no coherence dimension building” seems more promising for now.
Yeah. I was wondering if maybe you couldn’t have an internal statement of full coherence because the system was model invariant. This was a particular instance of the “model invariance is too strong” approach I described above. But that seems far fetched now. If you want model invariance, you can formulate some appropriate homotopy axioms as a type system. This doesn’t seem to rule out strict equality, provided you’re not too generous. So it should be OK. This is all based on practically nothing, of course.
Speaking of strict equality, is there discussion going on anywhere about adding strict equality other than by pursuing HTS, which you don’t seem to like?
Ah, I think maybe I see what you’re thinking of. Yes, one idea for showing model invariance, which I think I should attribute to Peter Lumsdaine, is to construct a ‘glued’ model relating the two models you want to compare, which is the same sort of thing you do when proving parametricity.
I don’t know any other proposals for strict equality.
I’m getting the intuitive sense (which may be wrong) that full coherence is an anti-modular thing. It’s not really a property of a path alone, it’s a property of a path as it relates to the whole system it exists in. If so, then because of the openness of type theory, it may be impossible to express a fully coherent path without something fundamentally different from ordinary paths. Specifically it seems like maybe the internal statement of a fully coherent path should just be a strict equality. That is, one that satisfies UIP. I’m thinking there mightn’t be any non-equivalent way to do it, because of the openness of type theory, which means we can’t internally enumerate all the stuff it’s coherent with. Definitional equality looks strict internally, but externally, it need not be. And really, UIP cannot do any worse than make equality “as useful as” definitional equality. The interpretation of this would be something like the [definitional equalities are fully coherent paths] possibility you raised at the end of the original post. So there may not be any harm in UIP except when it’s conflated with set-level equality. (I mean equality of set elements, which is externally strictly propositional.) Fully coherent paths between fixed endpoints would be unique in some sense, right? In other words, distinguishing them would be evil.
In this interpretation, the problem with having only strict equality isn’t that we collapsed the dimensions, but that we’ve lost our tool for talking about them non-evilly. This might be a helpful way of thinking about a system that combines strict and weak equality. (That the strict equalities are fully coherent.) And if semisimplicial types really do capture full coherence, then this point of view might somehow imply that semisimplicial types are impossible in the current ITT-based HoTT, because it somehow would require the system to be closed, or have UIP.
What do you think? Both about interpreting strict equality as fully coherent paths and about the hand-wavy argument why internal strict equality is necessary.
It’s certainly true that it doesn’t make sense to ask whether a single path is “coherent”: coherence is a property of a “system” rather than a single object. That said, I would expect to be able to exhibit “subsystems” that are coherent and remain coherent even if the ambient system is extended.
There are some examples in HoTT where we do know that a “fully coherent” structure can be presented internally. For instance, the definition of equivalences “ought” to involve two maps, two homotopies, two 2-homotopies, two 3-homotopies, and so on — but we know that it’s sufficient to stop after any finite odd number of these, the rest of them being uniquely (up to homotopy) determined. This generally happens when coherence can be expressed in terms of contractibility (or, more generally, hlevels) — so I suppose this could be saying something of the same thing as “an equality satisfying UIP”. But it doesn’t require introducing a new kind of equality, it’s just a statement that the ordinary equality on a particular type happens to satisfy UIP.
In category theory, the way we generally describe coherence is to say that all diagrams commute (or, more generally, describe which diagrams commute) in free structures of a certain sort (like monoidal categories). Then when working in a particular structure of that sort (like a monoidal category), to check whether a diagram commutes we check whether it is in the image of a map from a free structure, which is essentially to say that it doesn’t involve “accidental” coincidences. This particular structure could also have lots of additional structure, e.g. in addition to being monoidal it could be equipped with a monad and a comonad and a distributive law, etc., but as long as the diagram in question is in the image of a map from a free monoidal category, it commutes.
Yes, intuitively we should be able to construct coherent subsystems, but as you say, so far we have more luck when we get down to UIP eventually. When that happens, coherence in the subsystem is unavoidable because the paths are already coherent in the universe. But other than that, we’ve been having trouble. An interpreter would provide a powerful way to build coherent subsystems, if only we could get it to work.
I’m not claiming to have a strong argument why a separate strict equality is necessary to build certain coherent subsystems; just that it’d make it easier, that it’s intuitively nice to be able to point out fully coherent (in the universe) paths in a non-contractible type, and that it seems harmless to be able to propositionally capture the fully coherent paths that definitional equality already forces upon models.
To make sure we’re on the same page, a model would have 3 notions of equality.
1. Actual strict equalities, which I’m not proposing to use
2. Fully coherent paths: paths that are the interpretation of definitional equalities in the syntax, and correspond to elements of strict equality types
3. Other paths, which can correspond to elements of weak equality types
As far as why strict equality might be necessary, I was thinking of what you said:
Maybe I over-interpreted that, but internally expressing the full coherence of the universe should be impossible because of what I was saying about openness. If semisimplicial types would somehow enable that, then they should be impossible too.
Yes, I read about coherence on nlab, so I actually knew that. I appreciate that you are discussing this cutting edge issue with me, even though I don’t know as much of the background material as I probably should.
I don’t think so, at least not a priori. Coherence here is only talking about a particular subsystem, i.e. a particular structure on the universe (that corresponding to the type theory being modeled). So, like in the case of monoidal categories, adding new structure to the universe shouldn’t affect the coherence of the existing structure.
Anyway, it sounds like you’re proposing that if judgmental equalities are interpreted semantically by paths in the model, as I was proposing at the end of the post, then there’s no reason we couldn’t add a “strict equality” type to the theory being interpreted and have it also be interpreted by paths in the model. Is that right?
OK, that seems less magical. So then that idea doesn’t work. One less thing to worry about.
Yup.
Hey folks,
I got my act together and finished* the subset interpreter by assuming UIP. Maybe now we could have a discussion of where to go from here, or has everyone lost interest? 🙂 The code is still for regular Coq, using the standard library. I figure since it’s using UIP, there’s not much point porting it just yet.
* Because it’s a totality proof for a relation, it does approximately the right thing by definition. It’s surely too slow to test. (And I used “Qed” so it won’t run.) There are probably things I ought to prove about it, but haven’t.
Congrats!
Did you have to assume UIP globally, or just assume that the terms you’re interpreting are hSets? (I haven’t actually looked at the code much, but might find time to in the near future.)
Well I assumed UIP globally, which is a lot easier. I still think I could do something a little better, like I said before. For HoTT, I’d probably want to use funext instead of setoids.
Great!
Unfortunately, this comment thread is by now more like a Gordian knot than a thread. Would you be interested in writing a new blog post describing what you’ve done and what you’ve learned, to kick off a where-to-go-from here discussion?
I would love to! My only concern is that I also want to try to get a paper published about it, or something based on it, and I’m not sure if it would be considered publishable if it’s already been described online in detail. But I don’t know; I’m totally new to writing research articles.
I’m also looking for opinions about what journals or conferences might be interested in it and whether I should make it a beefier subset before it would be considered important. What do you think?
My experience is that having blogged about something makes no difference at all to publishing it later. I suppose it might be different in CS or other fields; I’d be interested to hear if anyone else has opinions to share.
I don’t think I can help you much about where to publish it, but maybe some more CS-y person will speak up. You could also ask that question in your blog post; maybe some people look at the new posts but not the comments on 5-month-old ones.
I’ve decided I can write a blog post.
I have some questions about what I should do:
How much detail should I have about the machinery of the current interpreter?
How much should I try to discuss the relevance to coherence problems?
How much should I talk about ideas I have for extended or alternative interpreters? (Keeping in mind that I’m not positive they’ll work.)
What is a good length for the post?
Thanks.
Great! I think the answer to your last question is the most important one: “long enough to convey the most important things you have to say, but short enough that people will read it.” (I often have trouble with the latter part myself.) My general advice would be to write first about what you know, and then see if there’s space left to speculate. As for detail, you could try to give a short non-technical overview at first, focusing on the conceptual points (and not assuming the reader has read any of the previous discussion), then perhaps (if you want) a slightly more technical roadmap to the code. But those are just ideas; there’s no one right way to write a blog post. (-:
After writing a long, boring draft, I realized the problem is that I don’t know which of the things I could say would be considered important to most of the readers of this blog. Unless you guys have something specific you’d like me to explain or discuss, I’m going to go for the shortest understandable statement of what I did that I can think of.
Did you ever manage this post?
Well it’s been so long that I don’t remember for sure, but I thought it was this post from about a week later:
One of my colleagues, regarding what is state-of-the-art among type theorists, agreed that the question is not yet settled (neither for typed nor untyped syntax), and pointed me at ‘Typed Syntactic Meta-programming’, by Dominique Devriesse and Frank Piessens (http://dl.acm.org/citation.cfm?id=2500575), saying:
Two Things, one certainly not a-propos of the present discussion, one tangential to a comment elsewhere on things like semisimplicial types:
Thing The First: If one of the administrators can edit the css for this page, styling for (li.comment) has an item “padding:0 0 0 56px;”, and I’ve found visible threadedness doesn’t suffer much if “56” is reduced to “30”, or “20”, or “12”, while readability improves greatly with each reduction (especially for deep replies).
Thing The Second: It may well be irrelevant to the present discussion, but I’ve put together some coq types that look very nearly like what is needed of a composition law on a graph to be a (weak, omega) category, in such a way that if one could exhibit that thing on (say) some small full subcategory of Type, then types for coherently commuting n-cubes come for free, for all n. Actually, you could almost say that that’s exactly what I settled on saying one should ask for, but really it isn’t, quite. The Gist of it : here. I’m currently trying to see if I can’t find a sneaky way to construct the cubical path groupoid of a space.
Sadly, wordpress.com seems to charge a ridiculous amount of money to let you change the CSS. Maybe someday we’ll host this blog on our own server, and we can implement that fix then. Before that day, it ought to be possible for individual users to do it themselves with Stylish, but I don’t have time right now to figure out how myself.
Your other idea is quite interesting, but I don’t think I believe yet that it gives you a coherent category. I’ll be a lot more impressed if you can prove the pentagon.
The pentagonator is going to take more time… goodness, but you have a knack for asking difficult questions! In the meantime, if you (or anyone here) find yourself with unexpected free time, you can try figuring out what the type of
CompAssoc (CatOfArrows w) (theNextW w) (CrossId f g) (CrossId g h) (CrossId h k)* “Really Means”, in that context. My own take on it is: it fails to be a pentagonator to the extent that you can pull a new proof of associativity from it. Whether that new proof really is new may clear up in the next dimensional level, or maybe things only get worse? I don’t know!* : um… sorry, I introduced some new terms. they’ll be in the next revision. Or one can try figuring out those, too!
Here’s a possible idea for a no-go theorem for raw-syntax interpreters: having an interpreter gives you a way to talk about judgmental equality for expressible terms: you can say “give me two raw terms A and B and a proof that ‘refl : A = B’ is well-typed”. If you can use this to prove what I’ll call an intensional taboo, something that is provable in HTS and/or extensional type theory but not MLTT, then you can prove that such interpreters don’t work in MLTT.
Here’s an example that I don’t think works: in HTS, if you have a fibrant nat with a non-fibrant eliminator, you can prove functional extensionality for that nat; as I posted on the mailing list a while ago, the equality decision procedure for nat works to show that either two nats are strictly equal, or there is no path between them. Thus you can turn any path between nats into a strict equality, use funext for strict equality, and turn that back into a path between functions, and you have functional extensionality for functions into nat.
If the well-typedness proofs used the interpretation function (which I don’t think they do), then I think we would have something like a fibrant nat with a non-fibrant eliminator. Hence for expressible functions, I think we’d be able to prove functional extensionality. For example, I think we’d be able to get [(fun x y => x + y) = (fun x y => y + x)], something that is known(?) to not be provable without assuming functional extensionality or something similarly strong.
However, you said you almost have a set-level interpreter from raw syntax into the universe working, right? If that’s the case, then we can’t violate any intensional taboos stronger than K while sticking to set-level mathematics. (Is it known that funext for nats isn’t provable from K?)
So I’m not hopeful that this will go anywhere, because we’d need an intensional taboo on, e.g., the universe, and a way to make use of it, which will probably require univalence. But I figured I’d comment with what I’ve thought about for the past 45 minutes, in case it gives someone else ideas.
Yeah, I’m not sure that sort of thing will work. First of all, the subset language I’m interpreting doesn’t actually have definitional equality. I think I could add it, and it would be interpreted as intensional propositional equality of maps from environment to result, but I’m not positive that would work. I’m pretty sure I can’t interpret definitional equality as propositional equality of results for all environments, since that would require function extensionality to handle congruence through binders.
Second, I don’t see how an interpreter gives us a useful way of reasoning with definitional equality. Sure, if we metatheoretically prove some definitional equality and interpret it, then meta-metatheoretically, the results (actually maps to results) of interpretation are indeed definitionally equal. But this is analogous to any function which maps multiple distinct inputs to intensionally equal outputs. I don’t see how this lets us prove new things.
You’re right that that’s not provable in ITT. In ITT, propositionally equality can be interpreted as definitional equality of all closed instances.
(fun x y=>x + y) = (fun x y=>y + x)is already closed, so any proof must be definitionally equal torefl, but that can’t be, because they have different normal forms, so they’re not definitionally equal, soreflwould be ill typed.It sure looks like it, since the only remaining hole is a missing coherence.
I’d say that the full interpreter wouldn’t let us violate any intensional taboos other than K when not sticking to set-level math. At set level, we already have UIP, so we don’t need a K axiom to re-prove it. But I think we’re getting at the same thing.
I’m pretty sure K doesn’t imply funext. I think you could handle K alone by translating to pure ITT:
Ubecomessig T:U,isSet T. Now you can translate K to a concrete proof that doesn’t use K. It only uses the set-ness of the type involved. This translation doesn’t affect functions, so funext would be unprovable for the same reason as before.The universe of sets is only provably closed under pi if you have functional extensionality. Otherwise you can’t prove that
isSet T -> isSet (A -> T). (This is trivially provable with K, though.) So there are some intensional taboos that are provable if you have either K or funext, but not without either.Oof, I forgot about that. This could actually be a problem for my interpreter. I’m not sure how big a problem yet.
It looks like I barely get away without funext or K, at least for this subset, because:
1. The language doesn’t have equality, so I can use whatever equality I want in the interpreter without changing the meaning. It looks like I need to switch to setoids.
2. The universe type in my subset is not guaranteed to be closed under anything, so I can leave equality in small types abstract (use Id), and demand that small types be sets.
But that’s an ugly hack.
I don’t know what you mean by “if the well-typedness proofs used the interpretation function”, but I don’t think you’d get a fibrant nat with a nonfibrant eliminator unless you “put it in by hand”. E.g. if we “express judgmental equality internally” in the way that you suggest, then given two functions f and g you could prove by induction on n that refl : f n = g n is well-typed for all n. But that won’t tell you that refl : f = g is well-typed unless you add such a rule to the judgmental equality of the object language. And in any case, if the interpretation maps judgmental equality to propositional equality (and I don’t see what else it could do, since it’s an internally defined function), you won’t actually get a judgmental equality out.
Please what programming language have you used here?
The code snippets in the post are an Agda-like pseudocode. My experiments were with Agda. Matt’s subsequent experiments were with Coq.
Random thought regarding “making the whole definition impossible unless you could define infinitely many functions in one mutual recursion”. What if we define the syntax simultaneously with the interpretation function, and using quining to “cheat” and get access to the (n+1)-level functions when defining the n-level functions?
I thought about something like that. I wasn’t optimistic. It seems like to actually manage to “cheat” you’d need to already have an interpreter, or a well-typed, quoted interpreter (which sounds even harder). But your idea might be better than whatever I had planned.
A well-typed quoted interpreter is inconsistent, unless it only interprets a subset of its own syntax: https://github.com/JasonGross/lob/blob/master/internal/mini-lob.agda#L63.
Any chance you could comment that code a bit? It looks quite interesting, and I can figure most of it out, but it would be really nice if your intent was documented. I would like to convince myself that your English interpretation and your Agda code really do match.
Yeah! Thank’s for giving me the push I needed to do this. Here’s a version with many comments: https://github.com/JasonGross/lob/blob/master/internal/mini-lob-poem.agda and here’s an even more minimalist version (with no comments): https://github.com/JasonGross/lob/blob/master/internal/mini-mini-lob.agda. The intent is showing that for a wide class of syntax representations (basically, anything whose interpretation doesn’t need to be modified when adding more “well-behaved” constructors), it’s consistent to assume Lӧb’s theorem. (There’s another formalization that proves Lӧb’s theorem from assuming quines, and another one that assumes only a quotation function, and some work on one that uses a more vanilla representation that is powerful enough to encode itself, but doesn’t assume such, but these last two are less clean.)
Right. On one hand, Agda could interpret the language you’re quining in, but on the other, it couldn’t interpret itself. So I guess you’re thinking of something different from what I was, which you’re pointing out wouldn’t work for another reason.
Semi-simplicial types don’t need to full power of Agda. If semi-simplicial types are definable in Agda then Agda can interpret a language powerful enough to define semi-simplicial types (trivially, just axiomatize them as a constructor). But this language still can’t support a quoted interpreter for itself.
Do you meant, “manage to ‘cheat'” or “manage to use ‘cheating’ to get semisimplicial types”? Because if you just mean the former, here’s qunies in 150 lines of Agda: https://github.com/JasonGross/lob/blob/master/internal/mini-quine.agda#L35
The latter. I don’t see how you’re planning to use quining for semisimplicial types. But that’s just me. It’s worth a shot, if you’re willing.
I don’t have any concrete ideas. It just seemed like this hammer might fit the nail of semi-simplicial types, if they require access to things you haven’t yet defined, so long as they only require access to those things in lazy/unevaluated forms.
OK. Unfortunately, so far, none of the ways I get stuck seem like nails for that hammer. (The only one I’ve actually developed is the one from my post, but I’ve thought about a few other approaches that seem to have similar problems.)
I wonder if Floris’ truncation-as-colimit trick could be adapted to help HoTT eat itself.
Mike talked about how it seemed that you’d need an infinity of higher constructors for a HIIT definition of strongly-typed syntax. Maybe if you had the term constructors, then some Florisian colimit to handle all the higher constructors, you’d end up with an hset, kind of like how Floris got an hprop.
Sounds complicated though, so I don’t want to try it yet. Also, it would leave the problem of plain intensional type theory eating itself unsolved.
Do any of the theorems on the non-existence of self-interpreters for total functional languages rule out certain approaches to the problem Mike and Matt are trying to solve? Can the arguments be adapted to show that there is in fact no solution? I’m talking about the sorts of things discussed here:
http://math.andrej.com/2016/01/04/a-brown-palsberg-self-interpreter-for-godels-system-t/
Of course, to model semi-simplicial types, one can probably make do with less than a full self-interpreter…
Belatedly responding to this: I think the Gödel/Löb obstacle is separate to the semisimplicial obstacle. Because it’s trivial to write an interpreter for fully-normalized terms of the simple types (empty, unit, bool, nat), Gödel/Löb proves that a language cannot prove itself to be normalizing. An essential part of the proof is that the construction of the self-interpreter needs to be able to interpret itself; I think the current record for bypassing the obstacle is adding three (five?) additional universes to the metatheory (so a metatheory with types up to Type_{n+5} can interpret an object theory with types up to Type_n), though it’s hypothesized that you only need one additional universe.
By contrast the semisimplicial obstacle seems to come up even when interpreting a significantly weaker object theory, and seems to apply to even to interpreting fully normalized terms. And it can be defeated by assuming axiom K, unlike Gödel/Löb.
Coming back to this after a while:
> On the other hand, we could add truncation constructors to *force* the types to be sets. (In the setoidy approach, we could do this by asserting that coercions along any two parallel equalities are equal.) This is more like what we do in the set-theoretic approach to semantics: the category of contexts is built out of syntax *quotiented* by the mere *relation* of judgmental equality. This would in particular make them fully coherent — but at what cost?
>
> […]
>
> In particular, by the recursion principle for higher inductive types, the clauses of these definitions corresponding to the path-constructors giving the judgmental equalities of the object theory must interpret them as *propositional* equalities in the ambient theory. (With the setoidy approach, we would define separate mutually recursive functions on `TyEq` and `TmEq` that do this interpretation.) However, if we included truncation constructors, then we’re sunk, because the universe is not a set.
I was thinking about this again recently, and the justification of this last sentence is not clear to me. Consider defining separate `TyEq` and `TmEq`, and then adding a single path constructor to `Ty` and `Tm` each saying that anything in the hProp-trunctation of `TyEq`/`TmEq` generates an path in `Ty`/`Tm`. That is, quotient `Ty` and `Tm` by the hProp-trunction of `TyEq`/`TmEq`, rather than quotienting by `TyEq`/`TmEq` and then adding an additional truncation constructor.
In this case, it seems like we are not sunk: we might hope to prove that any judgmental equality in the object theory can be interpreted into a propositional equality in the meta-theory, and further more that any two such interpretations are equal. Has this approach been tried? Am I missing something?
It seems to me that that would just move the problem of defining the interpretation function to the place where you have to interpret the hProp-truncation.
At the point where we’re interpreting the hProp truncation, say trying to prove that `forall (x y : Ty) (e1 e2 : TyEq x y), ap-TyInterp |e1| = ap-TyInterp |e2|`, we can surely do induction on `e1` and `e2`, and make use of the interpretations of we just defined. This is a nontrivial theorem to be sure, but where do we end up with infinite regress?
I guess the thing you’re claiming is that this doesn’t give us any new tools for proving the same theorem?
What about a strategy like this?
Before defining the interpretation function, we prove that the syntax is strongly normalizing, and that any syntax is TyEq to its normal form and that two syntaxes are TyEq iff their normal forms are. Then we prove that any interpreter that interprets the particular proofs of (TyEq x (norm x)) that we generate can be upgraded into an interpreter for all TyEq, by routing through `interp (TyEq x (norm x) @ interp (normals-TyEq-from-non-normals-TyEq) @ (interp (TyEq x (norm y))^` or similar. Now it seems to me we just need to prove that `normals-TyEq-from-non-normals-TyEq` always spits out `eq_refl` whenever the normals are equal (non-trivial, but maybe feasible?), and then … ?
Said another way, my understanding is that the standard problem is that we have no way to express judgmental coherency of the universe, and so we can’t get our hands on a gadget that gives us access to the infinitely many levels. But it seems to me that there *is* a way to express the coherency we want to have: for any `x y : Ty`, the *image* of `TyEq x y` under `TyEqInterp` should be an hProp.
Well, my standard response to anyone who thinks they have a solution to this problem is: okay, formalize it! (-:
Yeah, if only I had the time… Maybe sometime in the next 9.5 years 😉
> But it seems to me that there *is* a way to express the coherency we want to have: for any `x y : Ty`, the *image* of `TyEq x y` under `TyEqInterp` should be an hProp.
I think you have the right kind of intuition here. I was also trying an interpretation function based on this idea: The image of the interpretation is set level even though the codomain is not.
Because I seem to like working with the interpreter as a relation, I was thinking of it as gluing the syntax and semantics together. You have these packages of syntax, semantics, and a derivation connecting them. You can think of it as an interpretable expression, or “definable” semantics.
But of course, it’s not *merely definable* semantics. So it’s not really the image, internally. It has the syntax attached, and I was counting on it turning out to be set level.
What I was trying didn’t involve any truncation. The relation was supposed to be functional by construction, by using rules that get you unique derivations. More on that below.
I didn’t really follow what you were doing with truncation. If my approach would work as expected, something like TmEq or TyEq handling judgmental equality should already have a unique (glued) output.
I’ll try to explain what I mean by “functional” and “glued output”:
Consider the simplest function of all: the identity function. As a relation, it’s the equality/identity type family, and it’s generally *not* propositional. But clearly it always corresponds to a function anyway. How do we express that? Well first of all, lets say the left argument is the input and the right argument is the output.
Now, the set theoretic approach doesn’t work. That would be to say, for all LHSs, take the type of RHSs such that there *merely exists* an equality with the given LHS, that type is contractible. But too bad, it generally isn’t.
But with equality/identity types, we all learned what to do instead: For all LHSs, take the *sigma packages* of a RHS along with an equality with the given LHS. That is, the paths with one endpoint fixed. *Those* types are always contractible, by equality elimination.
So in general, I work with relations that are functional in that sort of sense: For all (dependent) tuples of inputs, any two “glued output” tuples for it are equal, where a glued output is a dependent tuple of outputs (in the usual sense of indexes to the relation) along with the derivation gluing them to the inputs. (Contractibility is like unique existence. I just want uniqueness. Given an input tuple, the type of glued outputs for it should be an hProp.)
Now, since the glued outputs are unique, if we combine them in the same tuple with the inputs, those tuples should work like the inputs alone, equality-wise. This is the domain on which the functional relation (partial function) is defined. So a glued output is, equality-wise, a mere proof that its input tuple is in the domain. Yet clearly we can project out the outputs!
So then, you want some nicer way to prove that an input tuple is in the domain. A totality proof (for the relation) converts that nicer sort of proof to a glued output.
For the interpretation relation. The nice way to prove the raw syntax is in the domain would naturally be an ordinary typing derivation. So then totality converts that derivation to a glued output, and you project out your interpretation.
The interpretation relation will of course be somewhat more complicated than the identity. Actually, so far, it seems to me that it will be phenomenally complex. But still, the rough idea is that if the relation is the graph of a partial function, you should be able to prove that glued outputs are unique.
Now here’s the catch: Since the derivation is part of the glued output, it *also* needs to be unique, intuitively. I noticed with my set theoretic interpreter, from that post, that the interpretation relation looks awfully similar to the typing relation. So I figured I’d better stick with relations that kinda look like *algorithmic* typing rules. With algorithmic rules, the derivations are, intuitively, traces of the execution of a deterministic algorithm, so they are unique.
What went wrong, roughly, with my old set theoretic interpreter, is that it’s only algorithmic if you ignore where the interpretation derivations (the glue) are coming from. I forget where exactly it cheated, but it did.
Puzzling over that, I decided that I don’t think an ordinary inductive family can express an algorithmic interpretation relation, if you count the glue. So my plan since then was to somehow get an inductive-inductive relation working. Intuitively, it would be the graph of a recursive-recursive function with an inductive-inductive domain.
End of Matt’s crazy plan, Chapter 1. 😉
New response, based on coding a very toy example:
We will also need decidable equality of the pre-truncated relation so that we get decidable equality of the truncated relation. Then we interpret the hProp-truncation by first doing transitivity with the interpretation of the decision procedure, then doing induction on the untruncated relation. We use the fact that having a relation at all means that the syntactic input to the interpretation function is equal (because the syntax is quotiented by the truncated relation), then use the standard trick with decidable equality to get that all the relations in sight must interpret to refl.
Come to think of it, if the pre-truncated relation is decidable, you don’t actually need to assume general truncation to get at the truncated version. You can just say the check succeeds. That makes me less worried about it. (And I don’t actually see truncation in the code anyway.)
But now I also don’t really get what you think you’re demonstrating. You’ve got a set of type codes and you prove equality is decidable; why bother with codes for equalities at all?
What I’m trying to demonstrate.
As I understand it, the core obstacle is that we can’t express the infinite coherence tow= er in our induction hypothesis. (Does this match with your understanding?).
One way of cashing this problem out is the following observation: if we define
image f := { y : B & merely { x : A & f x = y } }, it is not possible to pick out an infinitely coherent subtype of paths inimage funlessBis a set.However, we can still get our hands on something that acts like “an infinitely coherent subtype of paths in the image of f”. This is what I’m purporting to demonstrate.-level
(You make a good point that with decidable judgmental equality, we don’t need to truncate the relation, and if we have set-level normal forms, we don’t need a separate type for judgmental equality codes.)
There’s some messed up formatting from typing on my phone, let me know if there’s any place where Swype messed up enough that it’s not clear what I was intending.
So
merelyis propositional truncation? So what you’re saying here sounds like your no-go theorem from before.Yes, I knew this. I was trying to say so before.
Right. What I’ve been trying to say is that the glued outputs act like that. Gluing the syntax and semantics together gets you something that’s kind of like the image of the interpreter–in that you can project out the outputs–but it’s actually a subset of the input, so it’s an hSet, and the paths are fully coherent. In other words, my thing that acts like an “infinitely coherent subtype of paths” is paths between glued stuff.
Well sort of. That was the core obstacle, prior to any plan for overcoming it. But I’m saying my plan is trying to use the raw syntax and interpretation itself as a set level “open presentation” of the semantics (a kind of system of codes for the semantics), to express full coherence.
So that immediately leads to the next obstacle: that this is circular because it’s the interpretation itself that relies on full coherence.
The solution is that, intuitively, the interpretation functions are recursive-recursive, so that the interpretation can refer to itself just well enough to use itself as the expression of full coherence for those things that it needs to know are fully coherent.
Thanks.
Yes on both counts.
Ah, okay, sorry I missed this.
Interesting. Can you point me at (or reproduce) the type? How do you avoid holding a copy of the output?
Ah, neat! I think we’re on the same page now (at least insofar as I think we now both agree that my idea / obstacle / solution seems to be subsumed by yours/be about an earlier point in the process than yours is currently). Thanks for bearing with my questions / claims / explanations.
I replied less deeply nested so the column isn’t so narrow.
I also have an idea that still might work for all I know. I tried to formalize it a few years ago, and ran into a host of technical obstacles, but nothing that felt like an infinite regress or a brick wall. I postponed working on it, since it was taking too much time.
I could chat about it, but Jason sounds busy and Mike sounds skeptical.
Well, my default attitude by now is skepticism, since I’ve seen too many clever ideas eventually founder in unexpected places for similar reasons. So I’m not personally interested in discussing new ideas very much until they’ve been formalized, but I don’t want to discourage others from pursuing them. Maybe your idea will be the one that works; or even if not, it may have valuable spinoffs.
That sounds completely reasonable to me!
I am very busy, but I’m also quite interested in chatting, especially if you have a clear picture how to localize the current obstacle. I went back an looked at your post again, but I’m rusty on all the details.
My intuition is that we cannot hope to prove that the interpretation relation is an hProp (because I don’t think it is; I think we can transport the interpretation relation across a non-trivial path in the universe, such as
negb : bool = bool, and end up with a nontrivial inhabitant of the relation, though I’m not sure). I think instead we need to prove coherence/UIP somehow of only the image of reduction / judgmental equality. That is, I think we may want a type of codes for judgmental equality / substitution traces, be able to interpret these codes into equalities between interpretations, and then prove that given two equalities between interpretations *that come from codes*, the equalities must be equal? Does this fit with your idea at all? (Do you have a write-up somewhere of your idea / any kernel of insight in it / what gives cause for optimism with the idea?)> I am very busy, but I’m also quite interested in chatting, especially if you have a clear picture how to localize the current obstacle. I went back an looked at your post again, but I’m rusty on all the details.
Sure, I’ll chat!
I don’t know what you mean by “localize the current obstacle” though. Who’s obstacle? My obstacle was just that my idea got dauntingly complex, and I have other things to do.
I had plenty of other obstacles, but if I remember correctly, I had plans to address all of them.
My current plan is not that much like what I did in that post, except that the interpretation is first formulated as a relation. And by “relation”, I really mean type family, a proof-relevant relation.
> My intuition is that we cannot hope to prove that the interpretation relation is an hProp.
I agree with this. I don’t remember if I expected the relations to be propositional when I did the set level interpreter from the post. But I don’t expect that to work for HoTT.
> I think instead we need to prove coherence/UIP somehow of only the image of reduction / judgmental equality. That is, I think we may want a type of codes…
I think I agree with this too, roughly.
For my newer attempts, I was trying to just use raw terms as the codes. In hindsight, the kind of closed type codes I had in the post were a bad idea, even at the set level. In vanilla HoTT, I would guess it’s impossible to come up with a “closed” or “global” set level presentation like that, once the language has type variables. So my hope was that the interpretation itself can act as an “open” or “local” presentation.
> …type of codes for judgmental equality / substitution traces, be able to interpret these codes into equalities between interpretations, and then prove that given two equalities between interpretations *that come from codes*, the equalities must be equal?
Yes that’s the kind of thing I was trying to do!
Actually, for the language I’ve been trying to interpret, every term is already normal, without tricks like hereditary substitution, because there are no introduction forms.
But analogously, I am counting on interpretations of types and terms *that come from codes (syntax)* being elements of sets. *If* I were trying to interpret judgmental equality derivations, I would expect them to interpret as unique equalities, by tracking that they came from the syntax.
> Does this fit with your idea at all? (Do you have a write-up somewhere of your idea / any kernel of insight in it / what gives cause for optimism with the idea?)
It seems to fit quite well, like I tried to express above.
I have a digital pile of messy notes and unfinished code lying around. I also had a somewhat presentable explanation of my approach, to myself. I’ll try to paraphrase what I remember from it as this conversation progresses, rather than dump it in your lap without explanation. If we’re still on the same page deep into details, I guess I can put it up somewhere.
I have no really good cause for optimism. The approach sounds plausible to me, and I don’t see what might go wrong. But of course, that could just be because I’m dead wrong.
I’ve coded up a toy proof of concept of the idea that I’m claiming might be able to solve the semisimplicial problem here. This is very toy, just meant to be suggestive: it shows that we can build a “universe” with two types (unit and bool), interpret codes into the ambient universe
Type, have a syntax for paths between types (currently just refl, sym, and trans), interpret this syntax into propositional equality in the universe, and, importantly, prove that the image of this interpretation is coherent. Notably, this relies on having a set-level syntax of normal forms where judgmental equality on our type codes corresponds with ambient (meta-level) propositional equality on our set-level normal forms.The normal forms enjoy a nice pair of properties that do not simultaneously hold in general of either raw syntax, structured syntax, nor in the universe:
The coherent structure that we’re building here is notably not directly a coherent subtype of the universe. This is essential: we cannot possibly classify a coherent subtype of paths between points without forcing the points to be discrete, as the following no-go theorem shows:
We instead have to bypass this obstacle by classifying paths between points presented as being in the image of the interpretation function.
Mike, Matt, did either of your approaches involve proving and using decidable equality of syntax and showing that the substitution/reduction relation you were trying to interpret into the universe also gives rise to propositional equality between syntax?
I don’t remember details of everything I tried, but I’m pretty sure that at some point I found myself proving decidable equality of something.
I haven’t looked at your proof of concept yet. I’m particularly curious to see what you mean by “image”. For now, I’ll just address your ideas about using normal forms.
Like I said in another reply, for the language I was trying, all the terms are normal for free. So I’m not really as sure about what would happen to my approach, if there were nontrivial judgmental equality, as I am about what I’ve actually done so far. That being said…
I don’t think it’s actually strong normalization we need, or even decidable judgmental equality. Even if the equality test is partial, as long as it’s deterministic, in principle, we should be OK, since we will have a typing derivation telling us it’ll work. “Totality” on well-typed terms is the only kind that seems needed for an interpretation function.
In my approach, I expect the packages of syntax glued to semantics would have syntactic equality as their metalanguage equality, even in a typical case where judgmental equality is more extensional.
It doesn’t seem like there should be any problem having raw syntactic equality. Once you can get set level codes, somehow, having a judgmental equality relation on top feels like a relatively straightforward modification. In other words, syntactic equality is excessively intensional to be set level, but that means it’s plenty intensional enough.
The algorithmic interpretation relation for judgmental equality should intuitively always output eq_refl. But I don’t know how you’d prove that in any stronger sense than that glued outputs are unique.
Oh, I forgot to mention: Given equal glued outputs, the output tuples they contain are equal. That’s just the first projection’s action on paths. So intuitively it implies that those outputs that come from the relation for a given input are unique. But you can’t actually say that. Anyway, that’s my intuition for the “image” being set level.
You should take a look at the code, it’s only 56 lines, and you can ignore the 23 lines of proof which is mostly uninteresting.
Is there no way to delete duplicate comments that I misformatted?
You should take a look at the code, it’s only 56 lines, and you can ignore the 23 lines of proof which is mostly uninteresting.
That’s great, this is also the case in my toy code. This just means that the judgmental equality relation needs to imply propositional equality (at the meta level) of object terms, and that the object language needs to have (meta level) decidable equality.
I expect you need totality of the equality test to prove that composition of substitution is coherent. More concretely, I needed to know that it’s a contradiction to have a judgmental equality proof between terms that the equality test says “no” to, in order to handle coherency in the
transcase.Take a look at the code I wrote.
The theorem statement I have for this is
Inductive TY := BOOL | UNIT. Definition tyInterp (t : TY) := match t with BOOL => bool | UNIT => unit end. Inductive EQ : TY -> TY -> Type := | RFL {t} : EQ t t | SYM {a b} : EQ a b -> EQ b a | TRANS {a b c} : EQ a b -> EQ b c -> EQ a c . Fixpoint eqInterp {a b : TY} (p : EQ a b) : tyInterp a = tyInterp b Lemma eqInterp_K {a b p q} : @eqInterp a b p = @eqInterp a b q.What’s the formal statement that glued outputs are unique? Is this just stating that the relation is functional? I think you need something stronger than this: I think the translation of my intuition here is that you want to make a (set level) syntax for all the connections you use to prove uniqueness, so that instead of directly proving it with propositional equality you’re generating set-level syntax. You also show that this syntax gives rise to equality, and moreover it can give rise only to coherent equality, which is how you get the coherence assumption into your inductive argument.
> You should take a look at the code
OK. Did that.
> I expect you need totality of the equality test to prove that composition of substitution is coherent. More concretely, I needed to know that it’s a contradiction to have a judgmental equality proof between terms that the equality test says “no” to, in order to handle coherency in the `trans` case.
I’m not convinced.
First reason: Like I wrote in another reply, I don’t see why you even have equality codes for this example, since you prove decidability of actual equality.
Second reason: In my approach, where I expect I don’t need to prove decidability of judgmental equality, I use equality derivations. They’re kind of like your equality codes, I think, but the equality rules must be algorithmic. A `trans` rule is not algorithmic, so I’m not terribly surprised if it’s problematic.
> The theorem statement I have for this is…
> Lemma eqInterp_K {a b p q} : @eqInterp a b p = @eqInterp a b q.
Yeah, that kind of thing. But again, it seems weird to use equality codes, since you already have straight UIP for TY; no codes needed. Couldn’t you just do:
Definition eqInterp {a b : TY} (p : a = b) : tyInterp a = tyInterp b :=
Lemma eqInterp_K {a b p q} : @eqInterp a b p = @eqInterp a b q.
(Proof: Because p = q, because TY is an hSet.)
> What’s the formal statement that glued outputs are unique? Is this just stating that the relation is functional?
BTW, how do I get formatting here? I thought it used to be Markdown, but nothing’s happening.
So given:
A : Type
B : Type
R : A -> B -> Type
If we’re thinking of R as a functional relation with input A and output B, we should prove:
forall (a:A) (gb1 gb2 : Σ b:B, R a b), gb1 = gb2
gb1 and gb2 are two arbitrary glued outputs for input a. We prove that they’re equal.
> I think the translation of my intuition here is that you want to make a (set level) syntax for all the connections you use to prove uniqueness…
I don’t understand that. Can you rephrase?
> so that instead of directly proving it with propositional equality you’re generating set-level syntax.
Well I’m starting from raw syntax, which is definitely set level.
It kind of seems like we’re talking about different parts of my plan. I’m just saying how I deal with functional relations. Your example code doesn’t use functional relations, so the equality issues it deals with are a higher level issue than just proving a relation is functional.
> You also show that this syntax gives rise to equality, and moreover it can give rise only to coherent equality, which is how you get the coherence assumption into your inductive argument.
So let’s suppose, for the sake of explanation, that by magic or brilliance, I could actually define the interpretation function directly, and there’s no relational expression of it anymore.
It would be mapping from raw syntax and ordinary, proof-relevant typing derivations, to semantics. For example, you’d have a function for judgmental equality of (say) types, which inputs the type expressions and a derivation that they’re judgmentally equal, and outputs a (metalanguage) equality/path between the interpretations of the type expressions. Intuitively, the equalities coming out of the function are all coherent, because they come from set level syntax and derivations.
Now go back to my plan with functional relations: There’s a relation with those equalities as an index. I say the relation is functional by gluing those equalities to the inputs, and saying these glued equalities are unique.
I should also say that judgmental equality derivations are a set, but that’s not the hard part.
Part of my post disappeared because I tried angle brackets. Try again:
Definition eqInterp {a b : TY} (p : a = b) : tyInterp a = tyInterp b := (action on paths)
The content disappearing has the same root cause as this:
Use raw HTML for formatting, pre, code, blockquote, a href, em, ol, ul, li, etc. Not sure how to get math.
Ah OK. I must’ve been thinking of the nCat sites. Thanks.
Going to try to answer some questions now…
> decidable equality (and therefore is-hSet) (shared by raw syntax but not interpreted terms — is this true of structured syntax?)
By “structured syntax”, you mean something where you only have ASTs for terms that are well-typed in the object language?
The way they were originally done, without quotienting, I think equality would be syntactic equality, and would be decidable, but I’m not sure.
With quotienting, the idea is that equality is made to be the object language’s judgmental equality. Then I guess equality ought to be decidable if the object language’s judgmental equality is, but it sounds hard to prove. In any case, the quotienting approach set truncated the syntax.
Anyway, last I heard, the quotient style of intrinsically well-typed syntax doesn’t work (by itself, at least) for an interpretation in HoTT, because it has a set truncation constructor, which requires the elimination codomain to be a set.
> object-level judgmental equality corresponds with meta-level propositional equality (not true in general of raw syntax, true of the universe; is this true of structured syntax?)
Yes, if it’s the quotiented kind. See above.
> The coherent structure that we’re building here is notably not directly a coherent subtype of the universe.
Right! That’s why it can’t be literally an image of the interpretation function.
Umm, if I’m understanding you correctly, that is.
> Mike, Matt, did either of your approaches involve proving and using decidable equality of syntax and showing that the substitution/reduction relation you were trying to interpret into the universe also gives rise to propositional equality between syntax?
I was not planning to prove decidable equality of anything. Just uniqueness of equality. Very speculatively, if my idea about “open presentations” holds water, someone should try using infinitary syntax as an open presentation. This might justify what computational cubical type theory called “discrete” types, which are fibrant, and fibrant equality coincides with exact equality. These would correspond to the subsystem of *closed* infinitary terms. Of course, infinitary syntactic equality is not decidable, but with function extensionality, it still ought to be unique.
Umm, in my approach, the interpretation of a reduction relation would only get you equality of glued outputs, since the inputs are not-necessarily-normal syntax. Is that answering the second part of your question?
Substitution I was actually going to handle as a metalanguage operation. (That is, no explicit substitution calculus.) So it *should* work out syntactically. I think explicit substitutions could be made to work too (and then forcing substitution would not be syntactic equality), with my kind of approach, but it still has to be algorithmic. So I’m not sure it would simplify anything.
Speaking of normal forms, in a conversation with Mike I had in the past about interpretation, he seemed relatively optimistic about a canonical forms type system, where all well-typed terms are long normal. (I hope I’m remembering right. Feel free to correct me, Mike!) That way, syntactic equality coincides with judgmental equality, and something magic is supposed to happen. I know this is not what you’re calling for, Jason, but it reminded me.
With intrinsically well-typed syntax for a canonical forms system, metalanguage equality coincides with object language judgmental equality, without quotienting or set truncation. Maybe that’s where the magic would come from. But I don’t see what’s so important or magic about metalanguage equality coinciding with object language judgmental equality. It sure hasn’t made *my* wimpy object language easy to interpret.
Anyway, to me, it seems like a canonical forms system just moves the problem from explaining traditional judgmental equality to explaining the “hereditary substitution” that you need in order to avoid creating redexes. As a form of cut elimination, hereditary substitution is much fancier and more complicated than ordinary capture-avoiding substitution.
I would guess a canonical forms approach could also be made to work, but that nothing magic happens. Also, my impression is that in the presence of type variables, canonical forms systems get pretty gnarly.
The magic that happens, as I understand it, is that it makes it possible to phrase and prove coherency. If we want to avoid them, as I understand it, we need to quotient not by judgmental equality + set-truncation, but by the mere relation of hProp-truncated-judgmental-equality. We also need untruncated judgmental equality to be decidable so that the truncated relation is also decidable. If we have this, then we get a set-level syntax for normal forms with decidable equality. Hmmm, it seems I’m not quite sure how to pin down where the magic happens yet
Looking back, I didn’t say it very clearly. I said roughly equivalent things in two replies to other comments.
I wrote here:
And I wrote here:
You wrote:
Let’s look at my example again.
In response to:
I wrote:
So if
a:Ais an input andb:Bis an output, (R a b) is the type of derivations or glue that can connect them. Then (gb : Σ b:B, R a b) would be a glued output fora. (ab : Σ a:A, Σ b:B, R a b) would be a glued package of input and output.So assume
Ais an hSet, but no such assumption aboutB.– We prove that functionality statement from before. (With “
gb1 = gb2“.)– Thus (
Σ b:B, R a b) is an hProp for anya.– Thus (
Σ a:A, Σ b:B, R a b), the type of glued packages, is an hSet, and moreover a subset ofA.– That type is technically the domain of the partial function (represented by)
R, not an image.– Yet we can clearly project out the output. So we can “call”
R.– You can use the action on paths of projecting out the output, to get just a fully coherent subsystem of paths in
B. (These paths are just the ones sayingRgave the same output twice because it had the same input.)– If you need to deal with an arbitrary such path, you of course use a path in the set of glued packages, not an arbitrary path in
B.– More generally, you need to be really careful how you use elements of
Bif they’re not from glued packages.Hmm. Depends on what you mean. Computationally, I don’t: The output is right there for the projecting. But the glue binds things together. The glued outputs are all stuck to the input, like a generalization of a path with one endpoint fixed. A path with one endpoint fixed is a glued output for the identity. Up to homotopy, the information content of the output is removed.
I tried to explain this kind of functionality is my “Chapter 1” comment. Maybe you should take another look. Though I see now my explanation was incomplete and unclear in places, and you’ve drawn more out.