In chapter 2 of the HoTT book, we prove theorems (or, in a couple of cases, assert axioms) characterizing the equality types of all the standard type formers. For instance, we have

and
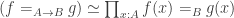
(that’s function extensionality) and
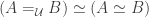
(that’s univalence). However, it’s a bit annoying that these are only equivalences (or, by univalence, propositional equalities). For one thing, it means we have to pass back and forth across them explicitly, which is tedious and messy. It may also seem intuitively as though the right-hand sides ought to be the definitions of the equality types on the left. What can be done?
One approach is to formulate alternative type theories in which the equality type, rather than being an inductively defined family, is defined externally “by recursion over types”. In other words, we observe that syntactically, the collection of types is inductively generated with the basic type formers as constructors, and so we can regard the above equivalences instead as the defining clauses of a function defined by recursion over this inductive definition. For instance, this is what Harper and Licata did in their paper Canonicity for 2-dimensional type theory.
However, this is an external induction, and thus requires modifying the type theory. We can’t do it inside of type theory, because internally, the universe is not inductively generated by the type formers.
Or is it?
It’s admittedly a bit weird that universes are the only one of the basic types that doesn’t come with an eliminator. I believe I read once that Martin-Löf considered giving the universe an eliminator, but eventually decided against it. There is a fairly obvious eliminator one could guess: since the type formers act like “introduction forms” for the universe, the eliminator should allow us to define a function out of the universe by induction on those. Which is exactly what we want to do at the moment.
So why doesn’t the universe have an eliminator? Some expert may be able to say more, but I believe one reason is that we want an “open” theory, i.e. we want to be able to add new type formers as needed. This is especially important when using type theory as a programming language, when we are defining new data types all the time. Writing all inductive definitions in terms of Sigma-types and W-types is theoretically possible, but extremely tedious. (And it’s unknown whether any similar reduction for HITs is possible.) But if the universe has an eliminator that matches against all type formers, then every time we write a new inductive definition, we would have to alter that eliminator, and add an extra clause to all of our functions that were defined using it.
Another reason the universe doesn’t have an eliminator is that the naive eliminator would contradict univalence. If the universe were inductively generated by type formers as constructors, then in particular the images of those constructors would be disjoint. Thus, for instance, a Σ-type could never equal a Π-type; but with univalence, this happens quite a lot.
A more traditional type theorist would probably express something similar by saying that an eliminator for the universe would break parametricity.
However, even in a type theory where the universe doesn’t have an eliminator, there is a way to construct a “universe” that does: by induction-recursion. This is, of course, one of the primary examples of induction-recursion: we define a new “universe type” U together with a recursive function 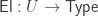
data U : Type El : U → Type data U where sig : (A : U) → (El A → U) → U pi : (A : U) → (El A → U) → U path : (A : U) → El A → El A → U El (sig A B) = Σ (El A) (λ a → El (B a)) El (pi A B) = Π (El A) (λ a → El (B a)) El (path A a b) = (a == b)
Note that when defining our IR universe, we just pick some collection of type formers for it to be “closed under”. Other type formers can exist, and be added to, the “real universe”, without it affecting our IR universe or the functions defined recursively over it. Specifically, we can now define a type-directed equality by recursion over U, internally to the type theory.
Unfortunately, however, U is not univalent, for the same reason mentioned above. But we know what to do when we have an inductive type with the wrong equality: use a higher inductive type to make its equality correct! We can add a path-constructor to U which makes two elements equal whenever their El types are equivalent — or equal, if we assume the ambient universe Type to be univalent. Then we have to include a corresponding defining clause showing how the function El acts on this path-constructor. Here’s some pseudo-Agda:
data U : Type El : U → Type data U where sig : (A : U) → (El A → U) → U pi : (A : U) → (El A → U) → U path : (A : U) → El A → El A → U ua : (A B : U) → (El A == El B) → A == B El (sig A B) = Σ (El A) (λ a → El (B a)) El (pi A B) = Π (El A) (λ a → El (B a)) El (path A a b) = (a == b) ap El (ua A B p) == p
I first had the idea of “higher-inductive-recursive univalent universes” over three years ago, but until very recently I thought we would also need a second path-constructor to complete the picture. In order for U to be univalent, the map 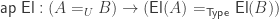
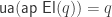
However, Peter Lumsdaine recently realized, in response to a question of Thorsten Altenkirch on the mailing list (who is apparently independently pursuing a similar idea to the one I’m talking about here), that this second path-constructor is unnecessary! The single path-constructor above is enough to make U univalent, since it makes the homotopy fibers of El into mere propositions, which is equivalent to saying that it induces an equivalence on equality types. This makes it much easier to work with.
So now we have a higher-inductive-recursive univalent universe; can we use it for type-directed definitions? Its induction principle says that yes, we can, as long as we show that the definition respects equivalence of types. For instance, we can define a new “equality type” by induction over type formers as long as we show, simultaneously, that our definition is invariant (up to equality, i.e. equivalence) under equivalence of types: e.g. that if some Σ-type is equivalent to some Π-type, then the rules for equality in Σ-types and for equality in Π-types produce equivalent results.
In order for this to work, we can’t just define our new equality types recursively on their own; we need to simultaneously prove something about them that characterizes them up to equivalence. I think the easiest candidate for this characterization is just to show that they’re equivalent to the ordinary equality types, using the theorems of Chapter 2 for each case.
With this modification, it works! We get a “computing” equality-type for elements of U, which (among other things) satisfies function extensionality and univalence judgmentally. The tradeoff is, unsurprisingly, that our new equality types only have an eliminator with a propositional computation rule. Some Agda code which implements this, based on the HoTT-Agda library and using the private types hack for the higher IR definition, is here (that’s in my Github fork), and formatted nicely for reading here.
It’s important to note that we can’t expect to be able to “define” the equality type of every type. For instance, there’s not much hope to be able to give a concrete description of the equality type of 
How far can this be extended? I think it should be possible to similarly define, say, composition of equalities in a type-directed way, so that (say) the composition of equalities between types is (judgmentally) just composition of equivalences, and so on. All the path-groupoid structure should work, as far up as we have the energy to push it. However, I don’t currently see any way to make the transport theorems of Chapter 2 work in this way, because they are type-directed definitions involving type families rather than just types. But I’d love to hear suggestions.
So what is this good for? Well, there are two ways we might be able to use it. On the one hand, we could stay inside the same type theory and just use our new universe U as “the universe” for all of our universe needs, replacing the “real” universe Type. (We can of course define a hierarchy of inductive-recursive universes as needed; indeed, they are much more flexible than the fixed countable sequence of universes that usually “comes standard” with a type theory.) On the other hand, we could regard this as a construction, starting from a model of “ordinary” type theory, of a new model of a different type theory in which equality types are defined by a type-directed recursion. Then we could feel free to use that other type theory, knowing that it’s consistent relative to, and can be interpreted into, the type theories we used to know and love.
Pedagogically, there’s something to be said for the former; if we were to imagine rewriting the book using the latter, we’d have to put parts of chapter 2 into chapter 1, which seems problematic. On the other hand, the former option requires Tarski universes (since U comes with an El, although we could choose to omit it from the notation), whereas the latter might work with Russell universes in the new theory. There are also other advantages to a type theory with basic type-directed equality, such as more hope of a computational interpretation (that being, for instance, what Harper and Licata were after). (Note, though, that this construction does not give a computational interpretation itself: partly because it fails to give meaning to things like transport, but mainly because it relies on already having univalence in the ambient universe Type.) Finally, in a formal implementation, it would probably be far too tedious to be worthwhile trying to actually use our U instead of Type in an existing proof assistant; but of course a new theory would require implementing a whole new proof assistant.
In conclusion, it’s not clear to me whether this idea actually buys us anything concrete at this stage of the game. Maybe it requires some more thinking and exploring to discover its value (if any). Let me end with one further comment about higher inductive-recursive universes.
Francois Dorais has pointed out that it’s kind of annoying to have only an externally indexed sequence of “God-given” universes. He also suggested one alternative involving one “super universe” that isn’t actually used for much except as a container for the universes that are used. His specific proposal has a slight issue in that lacking an internalization of judgmental/strict equality, one can’t define internally what it means to “be a universe” except in the “weakly a la Tarski” sense, which is probably good enough for everything but noticeably more cumbersome to use than a strictly a la Tarski universe. However, inductive-recursive universes are strictly a la Tarski. Thus, as long as the “super universe” is univalent and allows higher inductive-recursive definitions, we can obtain the advantages that Francois is looking for in this way. (Since Francois wants in particular to have ways to express large cardinal properties, it should be mentioned in passing that inductive-recursive universes on their own are considered about Mahlo in strength.)
Admittedly, it is a little annnoying to have the super universe around that plays no role other than to contain the universes we really care about. As Francois pointed out, the super universe is kind of like the “class of all sets” in a class-set theory like NBG or MK. One can imagine formulating a type theory that is more like ZF in that the “class of everything” isn’t as an actual object of the theory, but there doesn’t seem to be any way to do it without some kind of “polymorphism”: specifically, the ability for contexts to contain type variables. And at that point it’s not so clear whether anything is really being gained versus using a super universe. (I also can’t think of any way to construct models of such a theory except by modeling a super universe.)

> It’s admittedly a bit weird that universes are the only one of the
> basic types that doesn’t come with an eliminator.
For me a (Tarski) universe does come with an eliminator: El.
El takes an element of the universe and turn it into something usable (a type). And as expected there are reduction rules when the eliminator is applied to an introduction rule:
El(pi A B) -> Pi (x : El A) (El (B x))
Another reason why we may not want the universe to be inductively defined: it’s not the case in the standard set-model where the universe is interpreted as the set of all small sets.
You’re right about models; in fact, I can’t think of any way to build a universe with an induction principle in a model except by induction-recursion.
I’m not sure about regarding El on its own as an eliminator, though. According to the IR perspective, El is just one instance of the eliminator.
This is cool!
I’m a little unclear on why exactly univalence of the IR universe is necessary for doing type-directed definitions, though? That is, if we think of the IR universe as “names” for types, why do you need to know that equality of names is “right”? Is there a simple example where this is unavoidable?
I think we only need it if we want to treat the IR universe as “the universe”, which of course we want to be univalent. If we just regard its elements as “names” for types, then there’s no reason for it to be univalent — but then you might say that our definition is not actually type-directed but rather (name-for-type)-directed. (-:
Here’s a concrete example of something you can do with the HIR universe that I don’t think you can do with the IR universe. Since the HIR universe is univalent, we can define the universal cover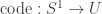 . Then we can apply the type-directed Path type and get that paths in code(base), which is (judgmentally)
. Then we can apply the type-directed Path type and get that paths in code(base), which is (judgmentally)  , are judgmentally equal to the recursive characterization of paths in
, are judgmentally equal to the recursive characterization of paths in  .
.
Also, re: transport my first thought is that the corresponding thing would be to introduce a syntax for type families, so you can recur over names for type families. So we’d need
data Ctx : Type
data U : Ctx -> Type
ElCtx : Ctx -> Type
El : (Gamma : Ctx) -> U Gamma → ElCtx Gamma -> Type
for some definition of Ctx—maybe do the four together as a higher inductive-inductive-recursive type, and use de bruijn indices into Ctx as variables? So El interpets U as a family ElCtx Gamma -> Type, which would be the family argument to transport. Depending on which transports we want to define, we might need to start giving a syntax for terms as well, but just doing Pi/Sigma/projections from Gamma and stopping at any types that have more complex terms in them would be a nice start.
The analogue of ua would be a “family extensionality” constructor
ua-fam : (Gamma : Ctx) (A B : U Gamma)
-> El Gamma A =_{ElCtx Gamma -> Type} El Gamma B
-> A =_{U Gamma} B
which says that if the interpretation of names as families are equal (which includes funext and univalence), then the corresponding codes are equal. I haven’t tried to write out the details of all the mutuality, but (1) do higher-inductive-inductive-recursive types make sense? and (2) would the above ‘ua-fam’ work as well as the ‘ua’ (in the sense of not needing an additional constructor to get the other side of the equivalence)?
That was the sort of thing I thought of at first too. But then I thought your U would need a constructor for substitution, and then you’d end up in coherence hell as in my last post. Can you think of how to deal with that?
As for your question (1), I haven’t thought about them much, but my guess would be that they ought to make sense as long as HII and HIR types do. I’m not sure about (2), but probably; is it an instance of the more general lemma that I called “ap-retraction-is-equiv” in my file?