Several current proof assistants, such as Agda and Epigram, provide uniqueness of identity proofs (UIP): any two proofs of the same propositional equality are themselves propositionally equal. Homotopy type theory generalizes this picture to account for higher-dimensional types, where UIP does not hold–e.g. a universe (type of types), where equality is taken to be isomorphism, and there can be many different isomorphisms between two types. On the other hand, Coq does not provide uniqueness of identity proofs (but nor does it allow you to define higher-dimensional types that contract it, except by adding axioms).
What determines whether UIP holds? The answer lies in two elimination rules for identity types, called J and K. J is the fundamental elimination rule for identity types, present in all (intensional) dependent type theories. Here is a statement of J, in Agda notation, writing Id x y for the identity (propositional equality) type, and Refl for reflexivity.
J : (A : Set) (C : (x y : A) -> Id x y -> Set)
-> ((x : A) -> C x x Refl)
-> (M N : A) (P : Id M N) -> C M N P
J A C b M .M Refl = b M
J reads like an induction principle: C is a predicate on on two propositionally equal terms. If you can give a branch b that, for each x, covers the case where the two terms are both x and related by reflexivity, then C holds for any two propositionally equal terms.
J certainly seems to say that the only proof of Id is reflexivity—it reduces a goal that talks about an arbitrary proof to one that just covers the case of reflexivity. So, you would expect UIP to be a consequence, right? After all, by analogy, the induction principle for natural numbers tells you that the only natural numbers are zero and successor of a nat.
Here’s where things get confusing: UIP is not a consequence of J, as shown by the first higher-dimensional interpretation of type theory, Hofmann and Streicher’s groupoid interpretation. This gives a model of type theory that validates J, but in which UIP does not hold. UIP can be added as an extra axiom, such as Streicher’s K:
K : (A : Set) (M : A) (C : Id M M -> Set)
-> C Refl
-> (loop : Id M M) -> C loop
K says that to prove a predicate about Id M M, it suffices to cover the case for reflexivity. From this, you can prove that any p : Id M M is equal to reflexivity, and from that you can prove that any p q : Id M N are propositionally equal (by reducing one to reflexivity using J). An alternative to adding this axiom is to allow the kind of dependent pattern matching present in Agda and Epigram, which allow you to define K.
So what is J really saying? And why is it valid in homotopy type theory? When there are more proofs of propositional equality than just reflexivity, why can you show something about all of them by just covering the case for reflexivity?
Find out after the cut!
To answer this question, we can reformulate J as follows (due to Paulin-Mohring), which corresponds to thinking of A and M as parameters Id{A} M N, and N as the only (non-uniform) index:
J : (A : Set) (M : A) (C : (y : A) -> Id M y -> Set)
-> C M Refl
-> (N : A) (P : Id M N) -> C N P
J A M C b .M Refl = b
This version holds one of the two terms, M, fixed throughout the rule. It is equivalent to the above (as long as you have function types around).
Next, we uncurry the predicate, and package the second term together with the propositional equality proof as follows:
PathFrom : {A : Set} -> A -> Set
PathFrom {A} M = Σ[ y ∶ A ] Id M y
J : (A : Set) (M : A) (C : PathFrom M -> Set)
-> C (M , Refl)
-> (P : PathFrom M) -> C P
J A M C b (.M , Refl) = b
In homotopy type theory, a type is interpreted as a topological space, where an element of the type is interpreted as a point in the space, and an identity proof as paths between the corresponding points. The type PathFrom M is defined to be a Σ-type, pairing a point y with a path (propositional equality proof) from M to y. This version of J says that, to prove something about an arbitrary path from M, it suffices to consider the case where the other endpoint is M itself, and the path is reflexivity.
That is, the real force of J is to assert that PathFrom M is inductively defined, with generator (M , Refl). For example, you can prove that any inhabitant of PathFrom M is propositionally equal to (M , Refl), and therefore that any two inhabitants of PathFrom M are propositionally equal.
And this principle holds even when there are non-reflexivity paths. The interpretation of propositional equalities between paths (i.e. of propositional equalities between propositional equalities) is homotopy (continuous deformation). The intuition for why J holds but K does not is that a PathFrom M has one endpoint free, which gives you additional freedom in how you can deform the path. To deform (N , P) into (M , Refl), you move the endpoint N over to M, while deforming the P into reflexivity.
For example, picture a circle in a space, with a hole on the inside of the circle. You can’t deform the circle into the identity loop on a point, because the hole gets in the way. But if you unhook one of the endpoints, you can drag it to the other, avoiding the hole, while deforming the path between them into the identity. The circle could be thought of a circle : Id base base, which is not homotopic (propositionally equal) to Refl : Id base base, contradicting K. However, (base , circle) is deformable into (base , Refl) at type PathFrom base.
Indeed, when doing proofs using J, the place where a proof will break down is often in choosing a predicate C that makes sense for all of PathFrom M, when the theorem you want to prove talks about a specific second endpoint. Go ahead and try proving K from J, or try proving directly using J that the higher fundamental groups are abelian. Choosing such a predicate is analogous to generalizing a theorem statement in such a way that an induction goes through.
This idea that PathFrom M is inductively defined is a new tool that homotopy type theory provides for the study of homotopy theory. For example, as type theorists know, you can define the rest of the groupoid structure on paths (composition, inverses, and the corresponding composition, unit, and inverse laws) from it–this is the usual implementation of transitivity, symmetry, etc. using J.
On the other hand, this understanding of J provides some insight into a well-known, but, honestly, somewhat strange, type-theoretic fact: the standard induction principle that you read off from an inductive family definition tells you how an arbitrary element of the family is generated, but it doesn’t (obviously) tell you about how the specific instances are generated. For example, here’s the definition of Fin n (numbers less than n) and the corresponding J-like induction principle:
data Fin : Nat -> Set where
fz : ∀ {n} -> Fin (S n)
fs : ∀ {n} -> Fin n -> Fin (S n)
fin-elim : (C : (n : Nat) -> Fin n -> Set)
-> (∀ n -> C (S n) fz)
-> (∀ n (f : Fin n) -> C n f -> C (S n) (fs f))
-> (n : Nat) (f : Fin n) -> C n f
The induction principle says that an arbitrary element of Fin n for an arbitrary n is either fz or fs. But it doesn’t directly tell you what to do with an element of say, Fin 0. For example, it’s tricky to prove that there are no inhabitants of Fin 0:
no-fin-z : Fin 0 -> Void
To do so using the above eliminator, you need to use a “large elimination” (a type computed by recursion on a term):
no-fin-z f = fin-elim Pred (\ _ -> ) (\ _ _ _ -> ) Z f where
Pred : (n : Nat) -> Fin n -> Set
Pred 0 f = Void
Pred (S _) _ = Unit
That is, you define a predicate that works for an entirely general element of the family by saying “when the instance of the family is the one I’m interested in, do the right thing, and otherwise do something that’s easy to prove”. A related idea is that, in Martin-Lof type theory without a universe, you cannot prove that the successor function is injective, because to do so you need a large elimination.
On the other hand, dependent pattern matching, as in Agda, effectively gives you the K-like elimination rules for each inductive family. For example, you can prove the above by giving a function with no cases:
no-fin-z/pm : Fin Z -> Void no-fin-z/pm ()
Indeed, dependent pattern matching can be reduced to an identity type with K; see Conor McBride’s thesis.
In sum, the J-like elimination rules leave open the question of what’s in each instance of the family. Sometimes, as with Fin, you can use them to answer this question, by computing with the indices. Other times, as with Id, you cannot. This is why J isn’t obviously nonsense in a type theory where there are more propositional equalities than just reflexivity; and the above intuition about deforming paths with a free endpoint is why it in fact makes sense.

Great article explaining some of the “magic” of the homotopical interpretation of intentional type theory!
However, it does make me wonder about the status of pattern-matching in a language like Agda, and how it can be generalized to homotopy type theory.
For example, K seems to holds for types with trivial fundamental group. So, depending on the h-level of the arguments in question, some form of dependent pattern matching can perhaps be rescued? What work has there been on this?
Good question! I don’t know of any actual results along those lines, but my intuition (with fingers crossed) is that it should work out. The reason is that, as you say, there is a large collection of types that *do* satisfy K, all of the “sets”. This includes natural numbers, booleans, lists, functions from one set to another, etc. In fact, this is basically all of the types you have in Agda/Coq right now. So the hope would be that you can allow non-uniform indexed inductive definitions for these types, equipped with dependent pattern matching as in Agda.
For non-uniform indexing by higher-dimensional types, I think that at a first cut it would be clearer to do it “by hand”, by using uniform indexing with an explicit propositional equality proof argument to the constructor. After all, the proof of equivalence that you give is computationally relevant.
But this all needs to be formally worked out.
You’re right that for simply-connected higher-dimensional types we have to remember the proof of simply-connectedness when K is invoked. However, perhaps a type-class-like mechanism could insert this automatically when needed?
Another question: Does it follow from Conor McBride’s (and others’) work that terms defined by pattern-matching in Agda
--without-Kcan be translated to type theory with only J-like elimination rules?Does it follow from Conor McBride’s (and others’) work that terms defined by pattern-matching in Agda –without-K can be translated to type theory with only J-like elimination rules?
I would very much like to know the answer to that! And also the same question for Coq’s pattern-matching operator.
Regarding Agda, it’s not a formal consequence of some existing work, but the conjecture is that the techniques should adapt to such a translation. But I would like someone to actually work it out, too. 🙂
For Coq, I think it is true that every Coq proof can be compiled to a term in the Calculus of Inductive Constructions. I believe that calculus has only J for identity types, so that should say that whatever you do can be translated to J under the hood.
Where can I read about things like compiling Coq proofs to CIC? I would just like to see a definition of what Coq’s “match” syntax translates to in terms of the corresponding eliminator “_rect” (like J); since Coq defines the latter in terms of the former, whereas type theory written on paper tends to take the latter as primitive.
You could give this a shot:
http://www.springerlink.com/content/y3h26w6274664m6m/
The details of the guard condition have changed, but this is still the “theoretical” justification of pattern matching in Coq.
So I think I was wrong about this translation existing, because CiC itself seems to include separate case-analysis and fixed point constructs; see the manual. We could ask on the Coq list if anyone has explained this in terms of eliminators. That is the language definition strategy used in Epigram, for example, but there you have UIP around, so it doesn’t directly tell you how to do Coq or Agda –without-K.
I’m pretty sure the above reference answers your questions: it gives a translation from guarded recursive definitions, a match construct being a degenerate case, and proves the operational equivalence of the two. Now fix points are used in the implementation, and recent meta-theoretical descriptions tend to privilege the latter description.
Hope is that in the relatively short term, the guarded recursion will be replaced by type based termination which allows more flexible recursive type definitions (see e.g. http://www.springerlink.com/content/w1ewj13ar199nd0t/). While it is clear that all functions definable from this approach remain definable in the CIC with eliminators, it is still an open question as to whether one can simulate them operationally (though this is likely the case).
Addendum to my above comment: i just saw the discussion on Coq-Club and indeed there is some trickery in the implementation of the guard condition that is not explained in the reference. Note that all this trickery is easily subsumed by type-based termination (it was invented for this purpose!).
This is a great explanation. However, I am left wondering why the first definition of J, which seems to treat x and y symmetrically, should “really” be regarded as saying something about the inductive generation of PathFrom M? A perhaps similar question is, what precisely is the difference between the definitions of
IdandFinwhich allows or prevents us from “answering the question of what’s in each instance”?To answer your first question, I’d argue that the Paulin-Mohring version of J is the best one, and the fact that the other is equivalent is not fundamental, just a theorem. The reason is that the identity type Id A M N is “parametrized” by A and M, but “indexed” by N. This terminology expresses the difference between “a family of inductively defined types” (where the arguments of the family are called parameters) and “an inductively defined family of types” (where the arguments are called indices). Parameters come before the ‘mu’ (for each choice of parameters, there is an inductive type). Indices are “in the loop”—you are simultaneously defining the whole family of types at once, so different instances of the family can refer to each other. As a consequence, indices can occur non-uniformly (e.g. in the result type of constructors), whereas parameters are fixed once and for all.
For identity types, the most precise thing we can say is:
module Identity {A : Set} (M : A) where data Path : A -> Set where Refl : Path M PathFrom : Set PathFrom = Σ[ y ∶ A ] Path y J : (C : PathFrom -> Set) -> C (M , Refl) -> (P : PathFrom) -> C P J C b (.M , Refl) = bThis expresses that, for each choice of A and M, we can define a family of types Path : A -> Set indexed by (N : A). In general, the induction principle for an inductively defined family of types tells you how to eliminate an arbitrary element of an arbitrary instance of the family, by giving cases for each constructor. I.e. for a family F : I -> Set, you it tells you what to do with Σ[ x ∶ I ] F x. In this specific case, this means that the elimination principle for Path tells you how PathFrom is generated.
Now, every parameter can trivially be viewed as an index that happens not to vary, which gets you to the more standard formulation of J. However, then what the induction principle is doing is telling you how Σ[ y : P ] Σ[ x ∶ I ] F y x is defined (writing P for the type of the params), but you know that this will always state things about an arbitrary first component of the pair (because it could have been a parameter). I.e. instead of saying “an arbitrary P : PathFrom M is (M,Refl)” you say “for any M, an element of the arrow category is equal to “.
The index formulation explains the asymmetry between M and N.
Okay, I think I see. The point is that the first definition of identity types contains a “trivial indexing”, like a non-dependent function viewed as a dependent one. So its corresponding induction principle is equivalent to the simpler one that we would get by recognizing that the trivial index is not actually varying. Is that right?
Yes, I think so! That’s my understanding, anyway. I understand it in this instance, but I’m not sure what the general story that lets you go back and forth between the parametrized and trivially indexed ones is, though.
I don’t see how this can be the case because Paulin-Mohring’s version of J seems to be stronger than the other one. In Agda (I hope this will work):
module Idquirk where -- So that we won't use any of the builtin elimination rules postulate Id : {A : Set} → A → A → Set Refl : {A : Set} {a : A} → Id a a Jα = {A : Set} (C : (x y : A) → Id x y → Set) → ((x : A) → C x x Refl) → (m n : A) (p : Id m n) → C m n p Jβ = {A : Set} (m : A) (C : (y : A) → Id m y → Set) → C m Refl → (n : A) (p : Id m n) → C n p JJ₁ : Jα → Jβ JJ₁ J m C b n p = {!J ? ? m n p!} -- not provable? JJ₂ : Jβ → Jα JJ₂ J C b m n p = J m (C m) (b m) n pThat direction is indeed trickier! See the original papers on Paulin-Mohring J, or see Section 1.12.2 of the HoTT book for one way to prove that they are equivalent.
Well, yes, but it only works in impredicative system like CoC. In predicative Agda it transforms into:
module Idquirk where open import Agda.Primitive postulate Id : {A : Set} → A → A → Set Refl : {A : Set} {a : A} → Id a a Jα : ∀ α → Set (lsuc α) Jα α = {A : Set} (C : (x y : A) → Id x y → Set α) → ((x : A) → C x x Refl) → (m n : A) (p : Id m n) → C m n p Jβ : ∀ α → Set (lsuc α) Jβ α = {A : Set} (m : A) (C : (y : A) → Id m y → Set α) → C m Refl → (n : A) (p : Id m n) → C n p JJ₁ : ∀ {α} → Jα (lsuc α) → Jβ α JJ₁ {α} J m C b n p = J (λ x y p' → (C₁ : ∀ z → Id x z → Set α) → C₁ x Refl → C₁ y p') (λ _ _ z → z) m n p C b JJ₂ : ∀ {α} → Jβ α → Jα α JJ₂ J C b m n p = J m (C m) (b m) n pwhich shows that Paulin-Mohring’s Jβ requires “larger” version of Jα.
Which is related to the fact that parameters in predicative systems can not be viewed as indexes that happen not to vary. The encoding actually packs indexes into constructors. Consider
data Fin : ℕ → Set where fzero : Fin (suc zero) fsuc : ∀ {n} → Fin n → Fin (suc n)which is encoded (with slight abuse of notation) as:
Now consider
which is just
And hypothetical (will not work in predicative system):
data Tree : Set → Set where leaf : {A : Set} → A → Tree A branch : {A : Set} → Tree A → Tree A → Tree Awhich would be encoded as
Also note that parameters are not outside of mu when encoded. If they were the following would be impossible:
in Haskell:
in Agda:
Some more comments, since as far as I can see there’s no way to edit the comment:
AFAIK modern Coq is predicative, so all af this holds there too.
Haskell is impredicative.
I agree with everything you are saying, but I don’t see what the problem is? In a HoTT context, I assume that an inductive family comes with large eliminations, so we always have a Jα that is one bigger than the Jbeta we are trying to construct.
Okay. In that case, my only problem is that I still disagree with the second half of the first paragraph of the second comment is this thread (starting with “Parameters come before the ‘mu’”).
In modern predicative Coq with universe polymorphism, I expect this will manifest as the fact that if you prove PM J from ML J, then the resulting PM J, although it will have the correct size itself, will take an extra larger “universe parameter” that gets used in its proof. As Dan says, this is not a problem theoretically; however the proliferation of universe parameters is a technical annoyance, so from a coding perspective it’s preferable to start with PM J rather than ML J.
I am not sure why Agda and Coq feel justified in treating A and B as parameters rather than indices in your OddTree example. I guess these are what people call “non-uniform parameters”? I used to think that that “non-uniform parameters” were just playing with words and syntactic sugar, allowing people to write things as parameters that really ought to be indices; but your point about universe levels makes me more worried than that. Can we actually construct an OddTree semantically without treating A and B as indices (and thereby blowing up the universe level)?
I guess one possibility would be to treat OddTree as syntactic sugar for a mutual inductive definition of OddTree and a copy of itself with A and B swapped. Is that always possible for “non-uniform parameters”? That would still keep A and B outside the .
.
And to answer your second question, I think that the difference is in what you know about the index type. The reason you can prove non-inhabitation of Fin 0 is that Nat has an elimination principle. The reason you can’t prove UIP from J is that the arbitrary A doesn’t. A related thing is that UIP is provable for all types with decidable equality.
I see, that makes sense. Although I think that to a homotopy theorist, “UIP is provable for all types with decidable equality” is a bit of a misleading thing to say, since nontrivial homotopy type theory is perfectly compatible with the natural logic of (-1)-types being Boolean; it’s only if we interpret “decidable equality” in the propositions-as-types logic that we get UIP. Right?
To me, decidable equality means
forall x y:A, x = y \/ x y
where = is propositional equality, and x y is (x = y -> void), forall is Pi and \/. The proof of this proposition is a decision procedure for equality at A. What is the other meaning of “decidable equality”?
Here’s a Coq development of the proof that types with decidable equality satisfy UIP. The basic idea is that, because equality is decidable, you can unify equate any two through the one that the decision procedure returns.
My point is that to a homotopy theorist, identity types shouldn’t be called “equality” but rather “path spaces”. A point of the type you wrote:
consists of a continuous function assigning to each pair of points, either a path between them or the assertion that there is no such path. I think to homotopical intution, it is “obvious” that if such a thing exists, then every component of A is contractible, i.e. A is a set.
I think it’s only in the propositions-as-types logic that it makes sense to interpret the above type as “for all x,y, either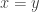 or
or 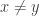 .” What I would call “equality” in the h-prop logic is not the path-space
.” What I would call “equality” in the h-prop logic is not the path-space  , but its h-prop reflection
, but its h-prop reflection  . And in an ambient classical logic, the corresponding proposition
. And in an ambient classical logic, the corresponding proposition
is always true.
I think that what this shows is *not* that either of the PAT interpretation of as identity or the homotopy interpretation as paths makes more sense than the other, but that each sheds a useful light on the other. Decidable equality is a familiar condition in constructive mathematics; the fact that the homotopy interpretation is sound allows us to see the connection between decidability and being a set. Then we can still use constructive reasoning to prove things formally about sets. Another example is that the law of excluded middle under PAT is equivalent to AC in predicate logic. We could say that the PAT interpretation of LEM is not “really” LEM but rather AC, but that would obscure this interesting connection between these two familiar principles, interpreted in two different ways.
as identity or the homotopy interpretation as paths makes more sense than the other, but that each sheds a useful light on the other. Decidable equality is a familiar condition in constructive mathematics; the fact that the homotopy interpretation is sound allows us to see the connection between decidability and being a set. Then we can still use constructive reasoning to prove things formally about sets. Another example is that the law of excluded middle under PAT is equivalent to AC in predicate logic. We could say that the PAT interpretation of LEM is not “really” LEM but rather AC, but that would obscure this interesting connection between these two familiar principles, interpreted in two different ways.
Yes, I think that’s what I intended to communicate by saying “to a homotopy theorist,” although it may have been a clumsy way to say it. I agree that each perspective sheds a useful light on the other, but in order for that to be successful I think each group needs to recognize the assumptions that the other brings.
To me, “decidable equality” is just a logical statement, whose meaning depends on the logic in which it is interpreted (or to be fancy, “the logic with which we enrich our type theory”). PAT is not the only possible such logic, even in constructive mathematics.
Thanks for helping reconcile our terminologies 🙂
To a computer scientist, a decidable predicate is one for which there is an algorithm that computes whether it is true or false. The nice thing about constructive logic is that “A is decidable” can be phrased logically as A \/ ~A. In classical logic, you have to talk explicitly about “algorithms” as subjects of propositions to define decidability.
But “logically decidable” does not entail “computably decidable” until you specify a particular “computational” way in which to interpret logic (like PAT). There are other interpretations of logic, which are still called “constructive,” in which concepts other than computability (such as continuity) play the central role.
Do you know if anyone has thought about groupoidal models of System F? The usual model construction for it is to take types to be partial equivalence relations on some set of realizers, and I’m curious if there’s a homotypical (or even just groupoidal) version of parametricity.
I would be very exited for an answer to this as well. Types can be interpreted by arbitrary relations (over terms), but a particularly interesting one happens to be “is beta-eta equal to” which seems to suggest that one could replace that with “there exists a path between”.
No, I don’t know of work on that, but I agree that it would be cool! For predicative polymorphism, it is a special case of the Hofmann/Streicher groupoid interpretation (read forall alpha.tau as Pi alpha:U.tau). But I don’t know of anyone who has considered the impredicative case.
Pingback: What’s Special About Identity Types | Homotopy Type Theory
Pingback: What’s Special About Identity Types | Homotopy Type Theory